Observability
Observe queries
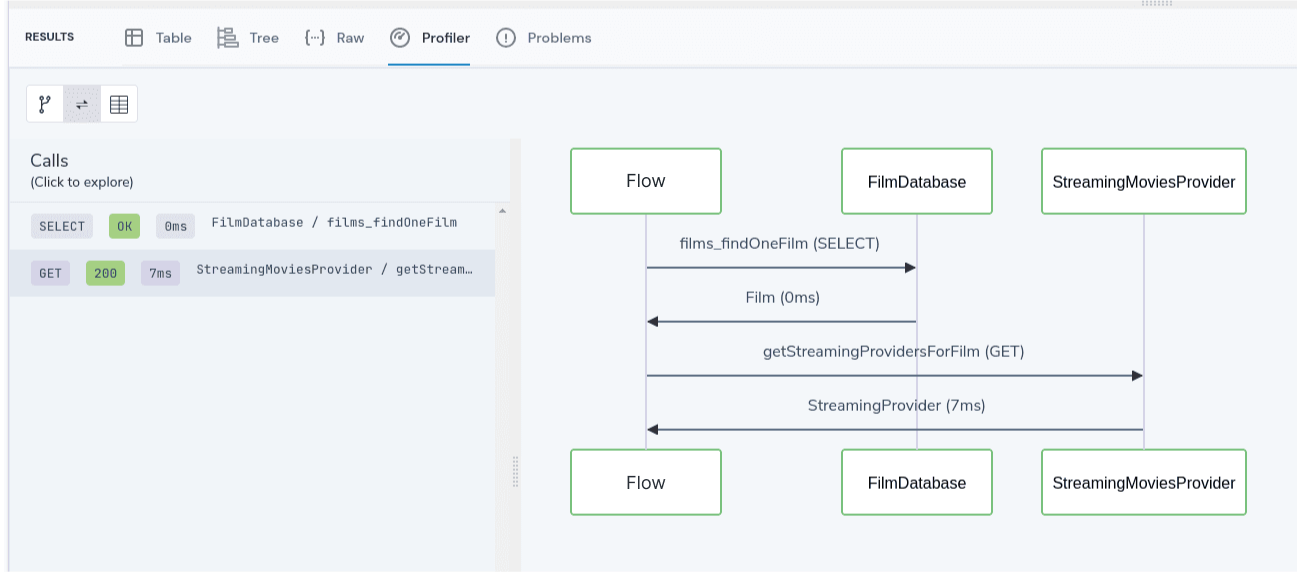
As queries are executed by Flow, full call histories are captured and persisted.
This gives rich debugging tools to understand exactly how a query was executed, which services were called and what they returned.
Configure what’s captured
The level of detail captured by Flow can be configured at startup, and entirely disabled, if desired.
When fully enabled, the following detail is captured and written to a database:
-
Requests and responses sent to services, such as APIs and databases
-
Metadata, such as URLs, response times, payload sizes, response codes and headers
-
Message payloads for streaming event sources, such as message brokers
-
Variations of the above data to build query plan charts visualized in the Flow UI
The following options can be passed as parameters or configured as environment variables to control the level of data that is persisted.
| Param | Description | Default |
|---|---|---|
|
Defines if responses from remote queries are persisted to the database |
|
|
The max payload written to the database per response |
|
|
Should metadata (URL, response codes, call durations) be persisted |
|
|
Should query results be persisted |
|
Performance metrics - Prometheus
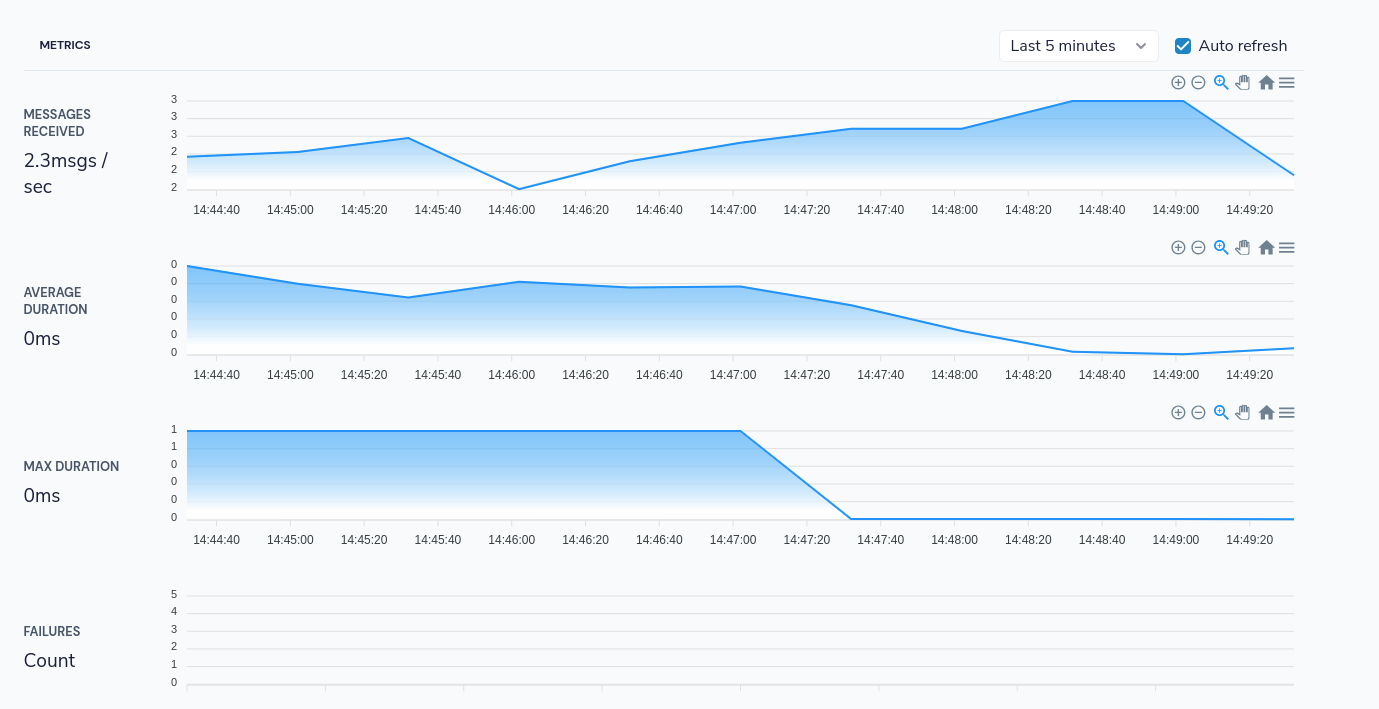
Flow publishes metrics available for Prometheus to collect.
If Flow is connected to a Prometheus endpoint, performance data is made available in the endpoint’s UI.
Stream queries
The following metrics are published for persistent queries (both streaming and request / response queries)
-
Count of requests processed
-
Processing duration
-
Error counts
Prometheus can then provide this data as a histogram, providing min / max and averages.
Configure Prometheus
An example Prometheus configuration is shown below:
scrape_configs:
- job_name: 'Flow Metrics'
metrics_path: '/api/actuator/prometheus'
scrape_interval: 3s
static_configs:
# 172.17.0.1 should be the ip address of localhost
# from within the container network
- targets: ['172.17.0.1:9021']
labels:
application: 'Flow'