Describe databases
Overview
Flow can connect to databases to fetch data when running a query.
To understand the data that is present in a database table, Flow uses a Taxi schema for that table. The Taxi schema describes the table, its columns and the data they hold.
Because we’re using Taxi here, the column descriptions are richer than things like String or Integer - instead using rich semantic tags like FirstName,
LastName, or EmailAddress
In this topic, we’ll learn how to create a Taxi schema for a specific database table, both through the user interface, and directly by editing a schema.
| Before you begin, make sure you’ve added a database connection for the table you want to connect. |
Use the UI
The UI allows you to connect a database table directly, without having to manually edit Taxi files. Through the UI, Flow will connect to the database, and create:
-
A series of types for each column in the database table
-
A model that describes the database table
-
A service that exposes query capabilities for the table
At this stage, only connecting new database tables in the UI is supported. To edit and remove existing tables, modify the Taxi schema directly. Support for editing via the UI will be shipped in a future release.
| Before continuing, make sure you’ve enabled schema editing through the UI. |
If you’re running through one of our tutorials, don’t worry, we’ve already configured this for you.
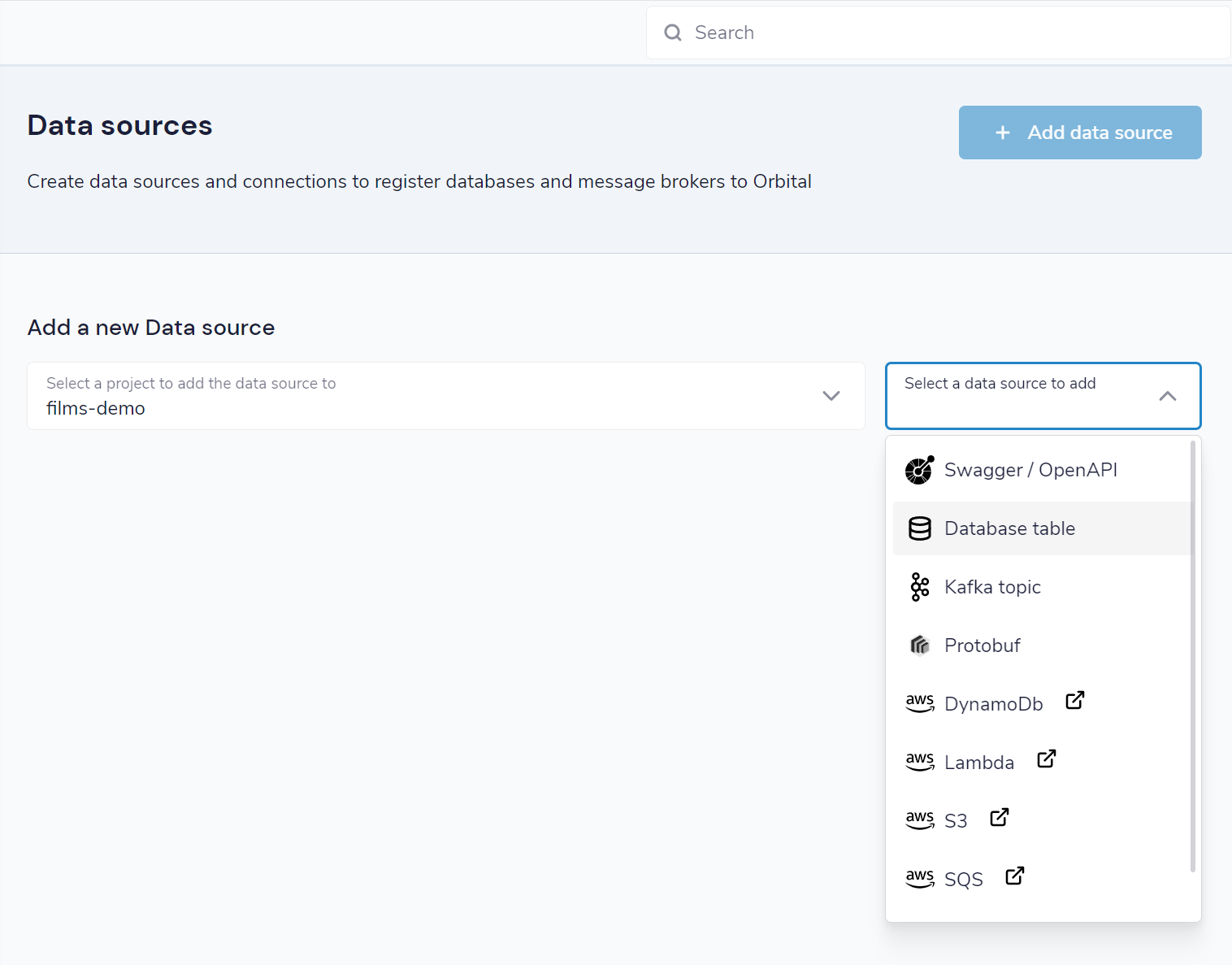
Import a new table
-
From the home page, click Add a data source.
-
Alternatively, click Data Sources in the left-hand navigation menu, then click Add data source
-
-
For the schema type to import, select Database table
-
Click the connection name dropdown, and select the connection for your database
-
If you haven’t yet created your connection, you can click Add new connection. For details, see add a database connection
-
-
Select the table from the dropdown
-
Specify a namespace for the Taxi types, models and services that will be created
-
Click Configure
Preview the generated types
A preview is shown, containing the models, fields and types that were imported from the database schema.
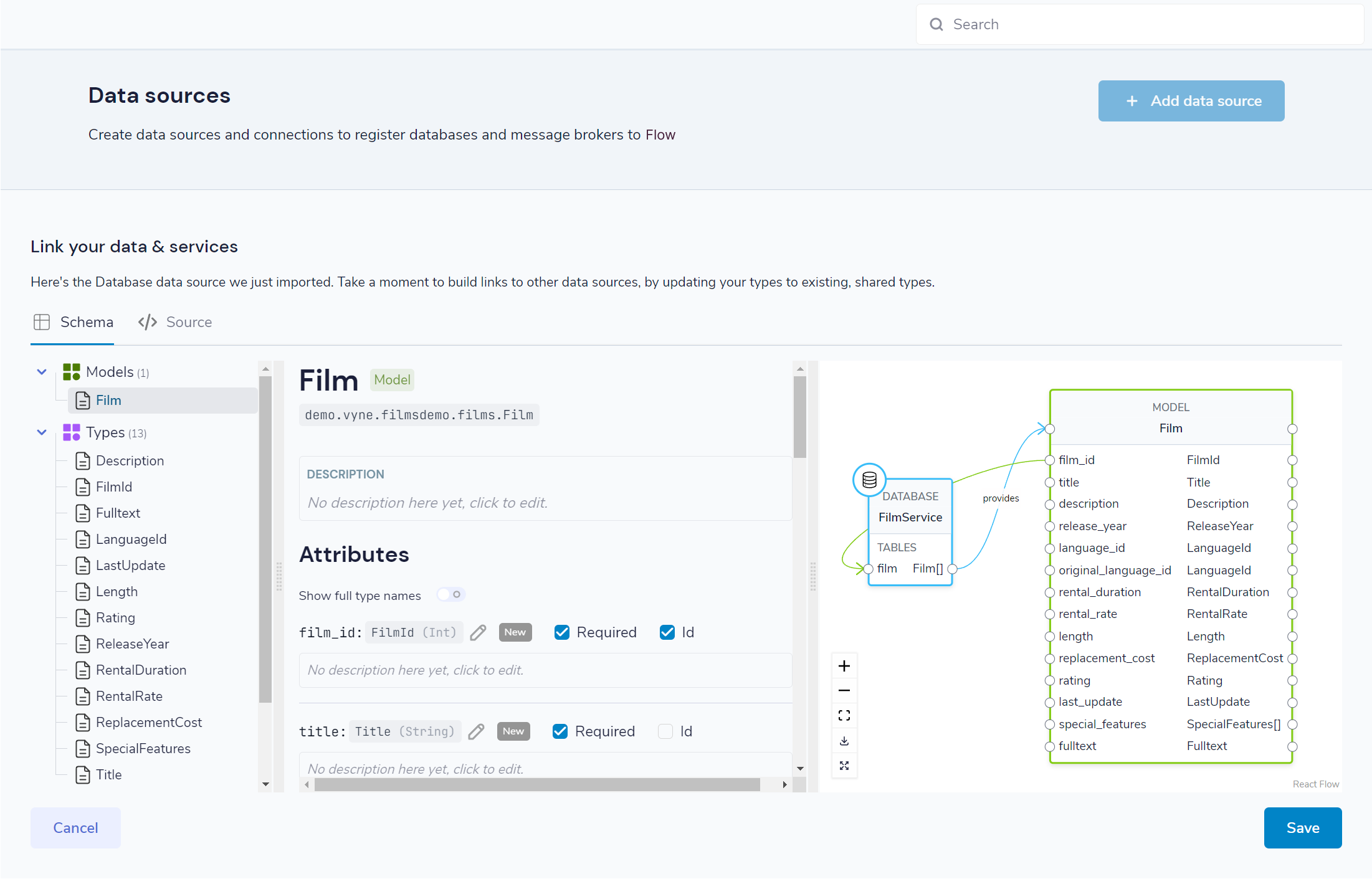
You can change any of the types (e.g., swapping a primitive type with a more specific semantic type), by clicking on the pencil icon next to the type name, and searching for the desired type.
Once you’re satisfied, click Save, and the schema will be updated.
Change the assigned types
Flow has assigned reasonable defaults to all the fields. Specifically:
-
IDs have been tagged
-
Foreign keys have been mapped
-
For all other fields, new semantic types have been created
If the columns in your database map to existing semantic types, you may wish to update the definitions. To do this:
-
Select a model from the table on the left-hand side
-
Click on the blue link for the column you wish to change the type of. A search dialog appears
-
From here, you can search for existing types in your catalog or create a new type
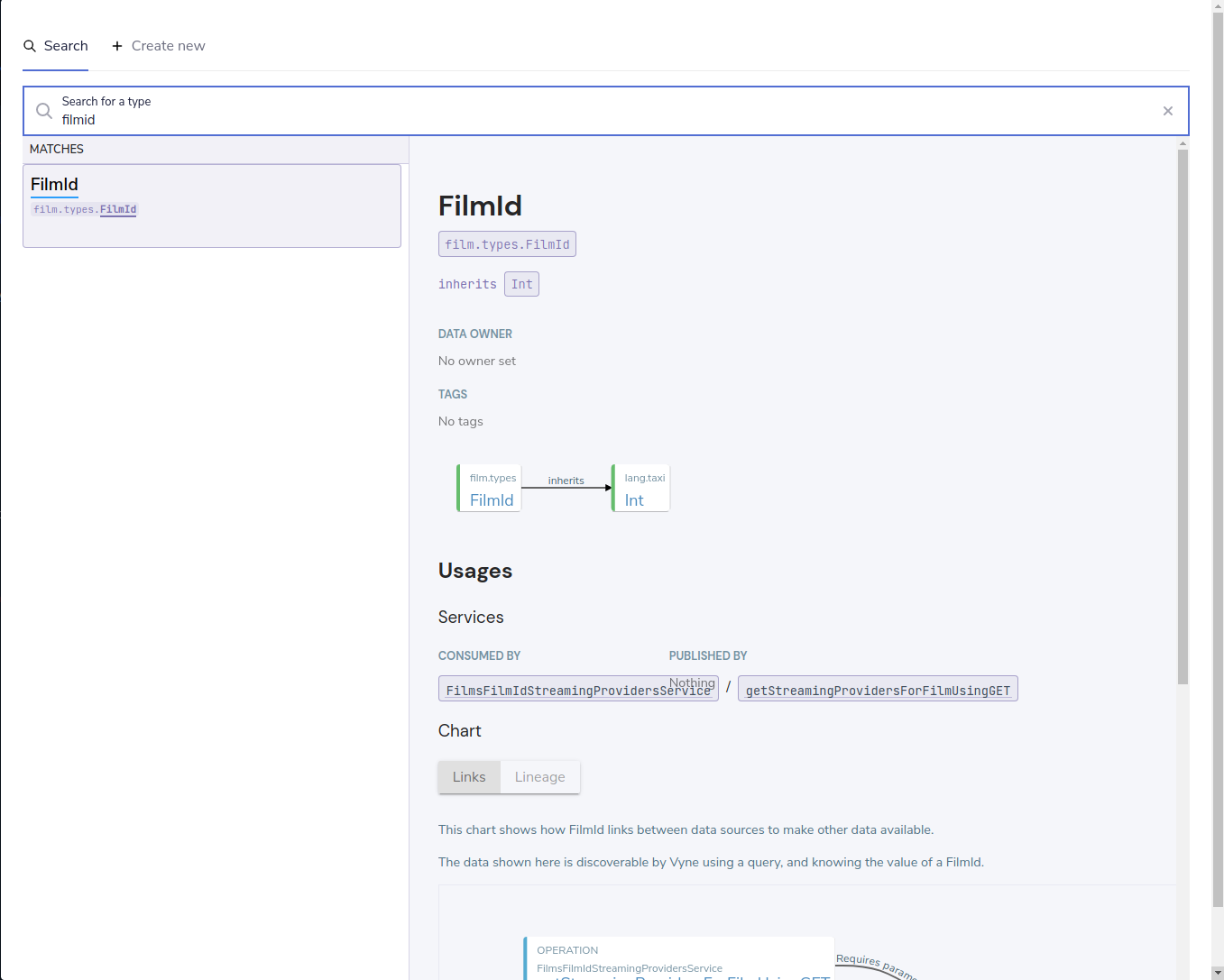
You can also click to edit documentation for any of the types, models and services.
-
Once you’re satisfied with the edits to your table and types, click Save
-
The schema is created and written to the Taxi project configured in your schema server
Required permissions
To view, create or edit connected database tables through the UI, users must have the following permissions granted:
| Activity | Required permission |
|---|---|
View the connected tables |
|
Create or modify a database table |
|
For more information on role-based security, see the topic on authorization.
Add a database data source manually
Instead of using the UI to add your database, you can add a database by defining a
a connection in your connections.conf file.
Here is an example for adding a Postgres database connection:
jdbc { // The root element for database connections
another-connection { // Defines a connection called "another-connection"
connectionName = another-connection // The name of the connection. Must match the key used above.
jdbcDriver = POSTGRES // Defines the driver to use. See below for the possible options
connectionParameters { // A list of connection parameters. The actual values here are defined by the driver selected.
database = transactions // The name of the database
host = our-db-server // The host of the database
password = super-secret // The password
port = "2003" // The port
username = jack // The username to connect with
}
}
}To see all the supported databases, and their connection configurations, read configure database connections.
Describe tables in Taxi
| Before you proceed, it’s worth understanding the basics of Taxi and how Flow uses it. Also, make sure you have a Taxi project set up, and that it’s been published to Flow. If you’re running through one of our tutorials, we’ve already taken care of this for you. |
Taxi files define the mappings of data models and the services that expose them. In this guide, we’ll describe how to expose a new database table to Flow, and make it queryable.
Before starting, in your Taxi project, create a new file under the src/ directory. It’s up to you what
you name it. For this example, customers.taxi is a good start.
Databases, and pull-based schema definitions
There are different ways for Flow to consume schema information - either by data sources pushing their information directly to Flow (well suited for application APIs), or by pulling from Git-based repositories that describe the schemas.
While the push model is preferred, it’s not currently supported for databases. We’re looking into ways to embed Taxi metadata into DDL schema definitions. For now, you’ll need to maintain a Taxi definition file that describes the database.
Define a table mapping
Tables are exposed to Flow using the annotation @flow.jdbc.Table on a model.
Field names in the model are expected to align with column names from the database.
Here’s an example:
import flow.jdbc.Table
@Table(connection = "films-database", schema = "public" , table = "customer" )
model Customer {
@Id // Use @Id to denote the primary key
customerId : CustomerId
firstName : CustomerFirstName? // Nullable columns should have the Taxi nullable symbol
lastName : CustomerLastName
}The @Table annotation contains the following parameters:
| Parameter | Description |
|---|---|
connection |
The name of a connection, as defined in your connections configuration file |
schema |
The name of the schema. Optional, depending on your database |
table |
The name of the table |
Query databases
To expose a database as a source for queries, the database must have a service and table operation exposed.
Here’s an example:
import com.flow.jdbc.DatabaseService
@DatabaseService(connection = "films-database")
service CustomerService {
table customers : Customer[]
}The @DatabaseService annotation contains the following parameters:
| Parameter | Description |
|---|---|
connection |
The name of a connection, as defined in your connections configuration file |
Sample queries
Fetch values by criteria:
find { Customer[]( DateOfBirth <= '1989-10-01' && CountryOfBirth == 'NZ' ) }Join two tables
find { Customer[] } as (customer:Customer) -> {
name : FirstName
// defines a join between the Customer and Purchase tables
purchases : Purchases[](CustomerId == customer.id)
}Join two tables, transforming data
find { Customer[] } as (customer:Customer) -> {
name : FirstName
// defines a join between the Customer and Purchase tables
purchases : Purchases[](CustomerId == customer.id) as {
// Inside this scope we have access to both Customer data and Purhcase data
productName : ProductName
price : ProductPrice
// Be sure to include the array marker, as we're defining an array of
// objects (Purchase[] -> OurType[])
}[] // <--- array marker
}Fetch from a database, enrich from another source
As with all TaxiQL queries, enriching data from multiple sources requires simply asking for the data you need - Flow works out the correct integration.
Assuming a schema with a database such as:
import flow.jdbc.Table
import flow.jdbc.DatabaseService
@Table(connection = "customers-database", schema = "public" , table = "customer" )
closed model Customer {
@Id
id : CustomerId inherits Int
name : CustomerName inherits String
}
@DatabaseService(connection = "customers-database")
service CustomerService {
table customers : Customer[]
}And we also have an API that exposes balance information:
closed model CustomerBalance {
customerId : CustomerId
balance : CurrentBalance
}
service AccountBalanceService {
@HttpOperation(url="https://fakeurl/customers/{id}/balance", method = "GET" )
operation getCustomerBalance(@PathVariable id:CustomerId):CustomerBalance
}The below call assumes we’re fetching customer details from our database, then enriching against an API call (API )
find { Customer(CustomerId == 123) } as {
name : CustomerName // this information comes from the database
currentBalance : CurrentBalance // An API call is made to fetch account balance
}Or, to fetch that same data for all customers:
find { Customer[] } as {
name : CustomerName // this information comes from the database
currentBalance : CurrentBalance // An API call is made to fetch account balance
}[]Write data to a database
To expose a database table for writes, you need to provide a write operation in a service,
specifying the write behavior:
import flow.jdbc.Table
import flow.jdbc.DatabaseService
import flow.jdbc.UpsertOperation
@Table(connection = "customers-database", schema = "public" , table = "customer" )
closed model Customer {
@Id
id : CustomerId inherits Int
name : CustomerName inherits String
}
@DatabaseService(connection = "customers-database")
service CustomerService {
table customers : Customer[]
@UpsertOperation
write operation saveCustomer(Customer):Customer
}In this example, the saveCustomer operation will attempt to perform an upsert.
| Write behavior | Annotation | Comments |
|---|---|---|
Insert |
|
|
Update |
|
Requires an |
Upsert |
|
Falls back to an insert if no |
Table creation
If the database table does not exist, Flow will create it when first attempting to write.
If the database table does exist, but with a different schema, writes may fail.
No schema migrations are performed.
Example queries
When writing data from one data source into a database, it’s not necessary for the data to align with the format of the persisted value.
Flow will automatically adapt the incoming data to the format required by the db.
This may involve projections and even calling additional services if needed.
Insert a static value into a database
// inserting a static value into a database
given { customer : Customer =
{
customerId : 123,
name : "Jimmy Smitts"
}
}
call CustomerService::saveCustomerStream data from Kafka into a database
import flow.jdbc.Table
import flow.jdbc.DatabaseService
import flow.jdbc.UpsertOperation
// Common, shared types:
type StockSymbol inherits String
type StockPrice inherits Decimal
// Database definitions:
@Table(connection = "prices-database", schema = "public" , table = "stock-price" )
closed model StockPrice {
@Id
symbol : StockSymbol
price : StockPrice
}
@DatabaseService(connection = "prices-database")
service PriceService {
table stockPrices : StockPrice[]
@UpsertOperation
write operation savePrice(StockPrice):StockPrice
}
// Kafka definitions:
// Note that field names don't align - {short-product-name}
// handles this for us.
closed model PriceUpdateMessage {
ticker : StockSymbol
lastTradedPrice : StockPrice
}Then, the query:
stream { PriceUpdateMessage }
call PriceService::savePriceFlow writes each message received from Kafka into the DB, creating the
table if required, and transforming the Kafka message to the format defined by
StockPrice.
