Work with XML and JSON
This tutorial shows how to link services that publish a mixture of XML and JSON. It explains how to combine these services and then expose them as a REST API.
How to begin a Hazelcast Flow project is described from scratch so, if you’re unfamiliar with Flow, this is the perfect starting point.
Typically, you’ll use Flow to stitch together services in different locations from across your organization but, to keep it simple, we’ve deployed these below as a single service.
Overview
This tutorial shows how to connect the following three services:
// A service that returns a list of Films (in XML)
operation findAllFilms():FilmList
// A service that returns the cast of a film (in XML)
operation findCast(FilmId):ActorList
// A service that returns the list of awards a film has won (in JSON)
operation findAwards(FilmId):Award[]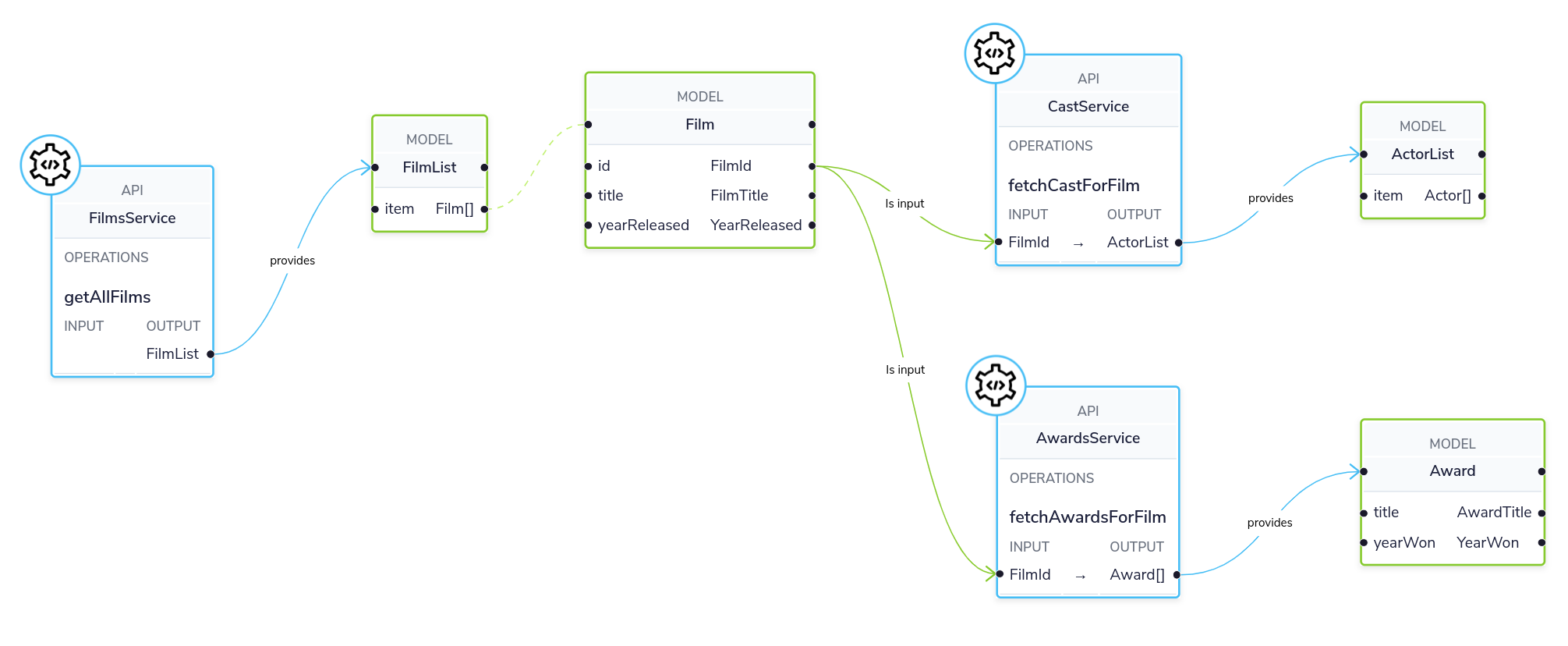
We’ll combine these together to create a single endpoint that exposes a REST API to return the data from all three services.
Set up
To get started with Flow, follow the instructions at Developer setup.
Create a new Taxi project, for example, called xml-and-json.
With Flow, instead of using integration code, schemas are used to describe data sources which Flow uses to link everything together. Some services publish their own schemas (e.g. XSDs or WSDLs) but the following example shows how to do this without schemas, with everything written in Taxi. If you have existing schemas, you can skip these steps.
Describe the Film Service
First, we’ll write Taxi code that describes our Film service. This is an HTTP operation that returns a list of films.
In the Taxi model, you’ll notice that the name of the field is composed of special types that will be used to share data across services and connect them together. This means we are not coupled to field names, which are free to change without impacting our model.
import flow.formats.Xml
// The @Xml annotation tells Flow how to read this object
@Xml
model FilmList {
item: Film[]
}
model Film {
id: FilmId inherits Int
title: FilmTitle inherits String
yearReleased: YearReleased inherits Int
}
service FilmsService {
@HttpOperation(url = "http://localhost:8044/films", method = "GET")
operation getAllFilms(): FilmList
}<List>
<item id="0">
<title>ACADEMY DINOSAUR</title>
<yearReleased>2005</yearReleased>
</item>
<item id="1">
<title>ACE GOLDFINGER</title>
<yearReleased>1975</yearReleased>
</item>
</List>| Once you have exposed this service, you will be able to see it in the Services diagram in Flow’s Catalog to view how everything links together. |
Next, copy this code into the Taxi project you created, for example, into a file called films.taxi.
Integrate the Cast Service
Next, repeat this process to define a Taxi schema for the film cast.
Our CastService takes the FilmId you created previously and uses this to return a list of actors:
import flow.formats.Xml
@Xml model ActorList {
item : Actor[]
}
model Actor {
id : ActorId inherits Int
name : ActorName inherits String
}
service CastService {
@HttpOperation(url = "http://localhost:8044/film/{filmId}/cast", method = "GET")
operation fetchCastForFilm(@PathVariable("filmId") filmId : FilmId):ActorList
}<List>
<item>
<id>34</id>
<name>JUDY DEAN</name>
</item>
<item>
<id>21</id>
<name>ELVIS MARX</name>
</item>
</List>What connects it together
Flow can now link our services together - there’s no need to write any integration code or resolvers as there is enough information contained in the schemas.
Tip: Use the Services diagram in Flow’s Catalog to view how everything links together.
// The FilmId from our Film model...
model Film {
id : FilmId inherits Int
...
}
// ... is used as an input to our fetchCastForFilm operation:
operation fetchCastForFilm(FilmId):ActorList
We’ve written more Taxi here than normal because we chose not to work with the service’s XSD directly (e.g., it wasn’t available, or it didn’t exist). If our services published XSDs or WSDLs, we could’ve leveraged those and only declared the Taxi scalars, such as FilmId.
|
Write Data Queries
Next, using Flow’s Query editor, write a query using TaxiQL.
Fetch the list of films
// Just fetch the ActorList
find { FilmList }Which returns:
{
"item": [
{
"id": 0,
"title": "ACADEMY DINOSAUR",
"yearReleased": 2005
},
{
"id": 1,
"title": "ACE GOLDFINGER",
"yearReleased": 1975
},
// snip
]
}Restructure the result
To remove the item wrapper (which is carried over from the XML format), we can change the query to just ask for a Film[]:
find { FilmList } as Film[]Which returns:
[
{
"id": 0,
"title": "ACADEMY DINOSAUR",
"yearReleased": 2005
},
{
"id": 1,
"title": "ACE GOLDFINGER",
"yearReleased": 1975
}
]Define a custom response object
We can define a data contract of the exact data we want back, specifying the field names we like, with the data type indicating where the data is sourced from. This means we are not bound to the source system’s descriptions.
find { FilmList } as (Film[]) -> {
filmId : FilmId
nameOfFilm : FilmTitle
} []Link our Actor Service
To include data from our CastService, we just ask for the actor information:
find { FilmList } as (Film[]) -> {
filmId : FilmId
nameOfFilm : FilmTitle
cast : Actor[]
} []Which now gives us:
{
"filmId": 0,
"nameOfFilm": "ACADEMY DINOSAUR",
"cast": [
{
"id": 18,
"name": "BOB FAWCETT"
},
{
"id": 28,
"name": "ALEC WAYNE"
},
//..snip
]
}Add our Awards Service
We can also define a schema and service for our awards information, which is returned in JSON:
model Award {
title: AwardTitle inherits String
yearWon: YearWon inherits Int
}
service AwardsService {
@HttpOperation(url = "http://localhost:8044/film/{filmId}/awards", method = "GET")
operation fetchAwardsForFilm(@PathVariable("filmId") filmId: FilmId): Award[]
}[
{
"title": "Best Makeup and Hairstyling",
"yearWon": 2020
},
{
"title": "Best Original Score",
"yearWon": 2020
},
// snip\...
]Enrich our query
Finally, to include this awards data, we just add it to our query:
find { FilmList } as (Film[]) -> {
filmId: FilmId
nameOfFilm: FilmTitle
cast: Actor[]
awards: Award[]
} []Which gives us:
{
"filmId": 0,
"nameOfFilm": "ACADEMY DINOSAUR",
"cast" : [] // omitted
"awards": [
{
"title": "Best Documentary Feature",
"yearWon": 2020
},
{
"title": "Best Supporting Actress",
"yearWon": 2020
},
]
}Publish our query as a REST API
Now that we’re happy with our response data, we can publish this query as a REST API.
-
First, we wrap the query in a
query { ... }block, and save it in our Taxi project -
Then we add an
@HttpOperation(...)annotation
@HttpOperation(url = '/api/q/filmsAndAwards', method = 'GET')
query filmsAndAwards {
find { FilmList } as (Film[]) -> {
filmId : FilmId
nameOfFilm : FilmTitle
awards : Award[]
cast : Actor[]
} []
}Our query is now available at http://localhost:9021/api/q/filmsAndAwards
$ curl http://localhost:9021/api/q/filmsAndAwards | jqWhich gives us:
[
{
"filmId": 0,
"nameOfFilm": "ACADEMY DINOSAUR",
"awards": [
{
"title": "Best Animated Feature",
"yearWon": 2020
},
{
"title": "Best Original Score for a Comedy",
"yearWon": 2020
},
{
"title": "Best Documentary Feature",
"yearWon": 2020
},
// .... snip
]
}
]Publish a query using the UI
To publish a query as an endpoint using the UI:
-
Choose Query editor and in the editor, write your query
-
Click Run to make sure the query runs with no errors
-
Click the Save query to project button, choose a project (this must be editable), give your query a name and then save it
-
Click the Publish endpoint button and publish it as an HTTP or WebSocket endpoint, depending on the query
-
Choose Endpoints and make sure the query is running (you can disable/enable the endpoint if necessary)
