Data Partitioning and Replication
Partitioning and replication are two common techniques used together in distributed systems to achieve scalable, available, and transparent data distribution.
By default, Hazelcast creates a single replica of each partition. You can configure Hazelcast so that each partition can have multiple replicas. One of these replicas is called primary and the others are called backups.
The cluster member that owns the primary replica of a partition is called the partition owner. When you read or write a particular data entry, you transparently talk to the partition owner that contains the data entry.
By default, Hazelcast offers 271 partitions. When you start a cluster with a single member, it owns all 271 partitions.
The amount of data entries that each partition can hold is limited by the physical capacity of your system.

When you start a second member in the same cluster, the partition replicas are distributed between both members.
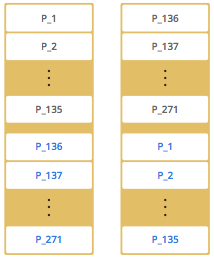
| Partitions are not usually distributed in any order, but are distributed randomly. Partition distributions are displayed in order for the sake of simplicity and for descriptive purposes. |
The partition replicas with black text are primaries and the partition replicas with blue text are backups. The first member has primary replicas of 135 partitions and each of these partitions are backed up by the second member. At the same time, the first member also has the backup replicas of the second member’s primary partition replicas.
As you add more members, Hazelcast moves some of the primary and backup partition replicas to the new members one by one, making all members equal and redundant. Thanks to the consistent hashing algorithm, only the minimum amount of partitions are moved to scale out Hazelcast.
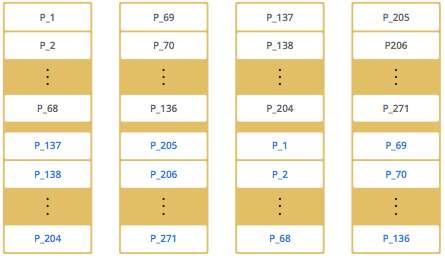
Hazelcast distributes the partitions' primary and backup replicas equally among cluster members. Backup replicas of the partitions are maintained for redundancy.
| Your data can have multiple copies on partition primaries and backups, depending on your backup count. See Making Your Map Data Safe. |
Lite Members
Hazelcast also offers lite members. These members do not own any partition. Lite members are intended for use in computationally-heavy task executions and listener registrations. Although they do not own any partitions, they can access partitions that are owned by other members in the cluster.
| See the Enabling Lite Members section. |
How Data is Partitioned
Hazelcast distributes data entries into the partitions using a hashing algorithm. Given an object key such as for a map or an object name such as for a topic:
-
the key or name is serialized (converted into a byte array)
-
this byte array is hashed
-
the result of the hash is mod by the number of partitions.
The result of this modulo - MOD(hash result, partition count) - is the partition in which the data will be stored, that is the partition ID. For all members you have in your cluster, the partition ID for a given key is always the same.
Partition Table
The partition table stores the partition IDs and the addresses of cluster members to which they belong. The purpose of this table is to make all members, including lite members, in the cluster aware of this information so that each member knows where the data is.
When you start your first member, a partition table is created within it. As you start additional members, that first member becomes the oldest member, also known as the master member and updates the partition table accordingly. This member periodically sends the partition table to all other members. This way, each member in the cluster is informed about any changes to partition ownership. The ownerships may be changed when, for example, a new member joins the cluster, or when a member leaves the cluster.
| If the master member goes down, the next oldest member sends the partition table information to the other ones. |
You can configure how often the member sends the partition table information
by using the hazelcast.partition.table.send.interval system property. By default, the frequency is 15 seconds.
Repartitioning
Repartitioning is the process of redistribution of partition ownerships. Hazelcast performs the repartitioning when a member joins or leaves the cluster.
In these cases, the partition table in the master member is updated with the new partition ownerships. If a lite member joins or leaves a cluster, repartitioning is not triggered since lite members do not own any partitions.
Replication Algorithm for AP Data Structures
For AP data structures, Hazelcast employs a combination of primary-copy and configurable lazy replication techniques. Each data entry is mapped to a single Hazelcast partition and put into replicas of that partition. One of the replicas is elected as the primary replica, which is responsible for performing operations on that partition. When you read or write a map entry, you transparently talk to the Hazelcast member to which the primary replica of the corresponding partition is assigned. This way, each request hits the most up-to-date version of a particular data entry in a stable cluster. Backup replicas stay in standby mode until the primary replica fails. Upon failure of the primary replica, one of the backup replicas is promoted to the primary role.
With lazy replication, when the primary replica receives an update operation for a key, it executes the update locally and propagates it to backup replicas. It marks each update with a logical timestamp so that backups apply them in the correct order and converge to the same state with the primary. Backup replicas can be used to scale reads with no strong consistency but monotonic reads guarantee. See Making Your Map Data Safe.
Two types of backup replication are available: sync and async. Despite what their names imply, both types are still implementations of the lazy (async) replication model. The only difference between sync and async is that, the former makes the caller block until backup updates are applied by backup replicas and acknowledgments are sent back to the caller, but the latter is just fire & forget. Number of sync and async backups are defined in the data structure configurations, and you can use a combination of sync and async backups.
When backup updates are propagated, the response of the execution, including
the number of sync backup updates, is sent to the caller and after receiving
the response, the caller waits to receive the specified number of
sync backup acknowledgements for a predefined timeout.
This timeout is 5 seconds by default and defined by
the system property hazelcast.operation.backup.timeout.millis.
A backup update can be missed because of a few reasons, such as a stale partition table information about a backup replica member, network interruption, or a member crash. That’s why sync backup acks require a timeout to give up. Regardless of being a sync or async backup, if a backup update is missed, the periodically running anti-entropy mechanism detects the inconsistency and synchronizes backup replicas with the primary. Also, the graceful shutdown procedure ensures that all backup replicas for partitions whose primary replicas are assigned to the shutting down member will be consistent.
In some cases, although the target member of an invocation is assumed to be
alive by the failure detector, the target may not execute the operation or
send the response back in time. Network splits, long pauses caused by
high load, GC or I/O (disk, network) can be listed as a few possible reasons.
When an invocation doesn’t receive any response from the member that owns
the primary replica, then invocation fails with an OperationTimeoutException.
This timeout is 2 minutes by default and defined by
the system property hazelcast.operation.call.timeout.millis.
When the timeout is passed, the result of the invocation will be indeterminate.
Execution Guarantees
Hazelcast, as an AP product, does not provide the exactly-once guarantee. In general, Hazelcast tends to be an at-least-once solution.
In the following failure case, the exactly-once guarantee can be broken: The target member of a pending invocation leaves the cluster while the invocation is waiting for a response, that invocation is re-submitted to its new target due to the new partition table. It can be that, it has already been executed on the leaving member and backup updates are propagated to the backup replicas, but the response is not received by the caller. If that happens, the operation will be executed twice.
In the following failure case, invocation state becomes indeterminate:
When an invocation does not receive a response in time,
invocation fails with an OperationTimeoutException. This exception does not
say anything about the outcome of the operation, meaning the operation may not be
executed at all, or it may be executed once or twice.
Throwing an IndeterminateOperationStateException
If the hazelcast.operation.fail.on.indeterminate.state system property is
enabled, a mutating operation throws an IndeterminateOperationStateException when
it encounters the following cases:
-
The operation fails on partition primary replica member with
MemberLeftException. In this case, the caller may not determine the status of the operation. It could happen that the primary replica executes the operation, but fails before replicating it to all the required backup replicas. Even if the caller receives backup acks from some backup replicas, it cannot decide if it has received all required ack responses, since it does not know how many acks it should wait for. -
There is at least one missing ack from the backup replicas for the given timeout duration. In this case, the caller knows that the operation is executed on the primary replica, but some backup may have missed it. It could be also a false-positive, if the backup timeout duration is configured with a very small value. However, Hazelcast’s active anti-entropy mechanism eventually kicks in and resolves durability of the write on all available backup replicas as long as the primary replica member is alive.
When an invocation fails with IndeterminateOperationStateException,
the system does not try to rollback the changes which are executed on healthy replicas.
Effect of a failed invocation may be even observed by another caller,
if the invocation has succeeded on the primary replica.
Hence, this new behavior does not guarantee linearizability.
However, if an invocation completes without IndeterminateOperationStateException when
the configuration is enabled, it is guaranteed that the operation has been
executed exactly-once on the primary replica and specified number of backup replicas of the partition.
Please note that IndeterminateOperationStateException does not apply to
read-only operations, such as map.get(). If a partition primary replica member crashes before
replying to a read-only operation, the operation is retried on the new owner of the primary replica.
Best-Effort Consistency
The replication algorithm for AP data structures enables Hazelcast clusters to offer high throughput. However, due to temporary situations in the system, such as network interruption, backup replicas can miss some updates and diverge from the primary. Backup replicas can also hit VM or long GC pauses, and fall behind the primary, which is a situation called as replication lag. If a Hazelcast partition primary replica member crashes while there is a replication lag between itself and the backups, strong consistency of the data can be lost.
Please note that CP systems can have similar problems as well. However, in a CP system, once a replica performs an update locally (i.e., commits the update), the underlying consensus algorithm guarantees durability of the update for the rest of the execution.
On the other hand, in AP systems like Hazelcast, a replica can perform an update locally, even if the update is not to be performed on other replicas. This is a fair trade-off to reduce amount of coordination among replicas and maintain high throughput & high availability of the system. These systems employ additional measurements to maintain consistency in a best-effort manner. In this regard, Hazelcast tries to minimize the effect of such scenarios using an active anti-entropy solution as follows:
-
Each Hazelcast member runs a periodic task in the background.
-
For each primary replica it is assigned, it creates a summary information and sends it to the backups.
-
Then, each backup member compares the summary information with its own data to see if it is up-to-date with the primary.
-
If a backup member detects a missing update, it triggers the synchronization process with the primary.
