Migration Guides
This appendix provides guidelines when upgrading to a new Hazelcast IMDG version. See also the release notes document for the changes for each Hazelcast IMDG release.
Migrating Between IMDG 3.12 and 4.0/4.1 Releases
Hazelcast IMDG Enterprise Feature
| If you want to migrate between 3.12 and 4.0/4.1 releases using this tool, you need to contact the Hazelcast Sales department at sales@hazelcast.com. Our existing Enterprise Edition users (IMDG Enterprise (4.x, 3.12.x) and IMDG Enterprise HD (3.12.x)) can contact support@hazelcast.com. |
This section outlines a solution for migrating user data from a running IMDG 3.12 cluster to a 4.0 or 4.1 cluster and vice versa using the migration tool, which is a specialized variant of Hazelcast’s WAN replication feature.
|
The migration tool introduces a new type of Hazelcast member instance, both for 3.12 and 4.0/4.1. We will distinguish between two types of members: "migration" and "plain" members.
The "migration" members are the instances which are available as non-public releases and are able to accept connections and packets from members of a different major version. They use more memory, have higher GC pressure and CPU usage in certain scenarios, all to be able to process messages from two different major versions.
On the other hand, "plain" members are the regular public releases with a minimal amount of compatibility code. In the examples going forward, we will be using any public 3.12.x release and any release from 4.0.2 onward. These artifacts can be downloaded from any of our standard distribution channels (Maven, website, …). The "plain" members are not able to accept connections and process messages from members of another major version. However, you might combine "plain" and "migration" members to form a single cluster.
In other words, "migration" members are simply new non-public Hazelcast releases which are compatible with "plain" or "regular" 3.12.z or 4.0.z members.
Example Migration Scenarios
Migrating from 3.12 to 4.0/4.1 (ACTIVE/PASSIVE):
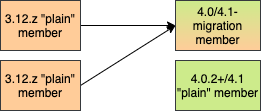
The diagram above outlines how you can perform the migration from 3.12 to a 4.0/4.1 cluster. Below we describe the diagram and process in more details. In case you are using an additional 3.12 cluster for Disaster Recovery (DR), please read the WAN Event Forwarding section for more information after reading this chapter.
-
The first step is to setup the 3.12 cluster. You can also use your existing 3.12 cluster. The members of the 3.12 cluster should have a minor version of at least 3.12 (any patch version). You need to setup WAN replication between the 3.12 and 4.0/4.1 clusters as stated in the 3rd step below.
-
Next, setup a 4.0/4.1 cluster. It must have at least one "migration" member and all other ("plain") members should be at least 4.0.2 and at most 4.1 (any patch version). The "migration" member can also be a "lite" member while the other "plain" members need not be. Making the "migration" member a "lite" member will also simplify further migration steps. The exact ratio of "migration" and "plain" members depends on your environment. In some cases it will not be possible to mix members of different "types" (or versions, for example in PCF) and in those cases you can create a cluster comprised entirely out of "migration" members. In other cases, the exact ratio of member types depends on parameters such as the map and cache mutation rate on the source cluster, the WAN tuning parameters, the resources given to the 4.0/4.1 cluster members, the load on the 4.0/4.1 cluster which isn’t related to the migration process, if "migration" members are lite members or not and many more. A good rule of thumb is starting with the same number of "migration" members as the number of members which are usually involved in WAN replication (if you were already using WAN replication to replicate data between different clusters) or to simply use an equal number of "migration" and "plain" members and then decrease the number of "migration" members if testing the migration scenario shows that the decreased number can handle the migration load.
-
Add WAN replication between the two clusters. As always, this can be done using the static configuration and can be added dynamically. The key point is that the 3.12 cluster needs to replicate only to the "migration" members of the 4.0/4.1 cluster. Other "plain" members are unable to process messages from 3.12 members and WAN replication must not replicate to these members. Other than that, the WAN replication configuration on the 3.12 cluster is the same as any other WAN replication towards a 3.12 cluster and no special configuration is needed. See also the WAN Replication section for the details.
-
After the clusters have been started and WAN replication has been added, you can use WAN sync for
IMapor wait until enough entries have been replicated in case ofIMaporICache. -
After enough data has been replicated to the 4.0/4.1 cluster, you can shut down the 3.12 cluster. You can check if your map data is in sync by using merkle tree sync with the caveat that in some edge cases, the merkle tree consistency check may indicate that the clusters are out-of-sync while in reality they are actually in-sync. In other cases, once WAN sync completes successfully and if there are no errors, the map data should be synchronized. See Limitations and Known Issues section for more information when using merkle trees for consistency checks.
-
Finally, you can simply shut down the 4.0/4.1 "migration" members or do a rolling restart of these members to "plain" members. If your 4.0/4.1 cluster was comprised entirely out of "migration" members, you will need to do a rolling restart of the entire cluster (for example, when migrating in PCF). At this point, the 4.0/4.1 cluster should have only "plain" members. You can also can continue using this cluster or continue onto rolling upgrade to 4.2, for instance.
Migrating from 4.0/4.1 to 3.12 (ACTIVE/PASSIVE):

The diagram above outlines how you can perform the migration from 4.0/4.1 to a 3.12 cluster. In case you are using an additional 4.0/4.1 cluster for Disaster Recovery (DR), please read the WAN Event Forwarding section for more information after reading this chapter. The process is analogous to the 3.12 → 4.0/4.1 migration but we will describe the diagram and process in more details below:
-
The first step is to set up the 4.0/4.1 cluster. You can also use an existing 4.0/4.1 cluster. The members of the 4.0/4.1 cluster should be at least 4.0.2 and at most 4.1 (any patch version). You need to set up WAN replication between the 4.0/4.1 cluster and the 3.12 cluster but this will be described soon.
-
Next, set up a 3.12 cluster. It must have at least one "migration" member and all other ("plain") members should have a version of 3.12 (any patch level). The "migration" member can also be a "lite" member while other "plain" members need not be. Making the "migration" member a "lite" member will also simplify further migration steps. The exact ratio of "migration" and "plain" members depends on your environment. In some cases it will not be possible to mix members of different "types" (or versions, for example in PCF) and in those cases you can create a cluster comprised entirely out of "migration" members. In other cases, the exact ratio of member types depends on parameters such as the map and cache mutation rate on the source cluster, the WAN tuning parameters, the resources given to the 3.12 cluster members, the load on the 3.12 cluster which isn’t related to the migration process, if "migration" members are lite members or not and many more. A good rule of thumb is starting with the same number of "migration" members as the number of members which are usually involved in WAN replication (if you were already using WAN replication to replicate data between different clusters) or to simply use an equal number of "migration" and "plain" members and then decrease the number of "migration" members if testing the migration scenario shows that the decreased number can handle the migration load.
-
Set up WAN replication between the two clusters. As always, this can be done using static configuration and can be added dynamically. The key point is that the 4.0/4.1 cluster needs to replicate only to the "migration" members of the 3.12 cluster. Other "plain" members are unable to process messages from 4.0/4.1 members and WAN replication must not replicate to these members. Other than that, the WAN replication configuration on the 4.0/4.1 cluster is the same as any other WAN replication towards a 4.0/4.1 cluster and no special configuration is needed.
-
After the clusters have been started and WAN replication has been added, you can use WAN sync for
IMapor wait until enough entries have been replicated in case ofIMaporICache.You can check if your map data is in sync by using merkle tree sync with the caveat that in some edge cases, the merkle tree consistency check may indicate that the clusters are out-of-sync while in reality they are actually in-sync. In other cases, once WAN sync completes successfully and if there are no errors, the map data should be synchronized. See Limitations and Known Issues section for more information when using merkle trees for consistency checks. -
After enough data has been replicated to the 3.12 cluster, you can shut down the 4.0/4.1 cluster.
-
Finally, you can simply shut down the 3.12 "migration" members or do a rolling restart of these members to "plain" members. If your 3.12 cluster was comprised entirely out of "migration" members, you will need to do a rolling restart of the entire cluster (for example, when migrating in PCF). At this point, the 3.12 cluster should have only "plain" members.
Bidirectional Migrating between 3.12 and 4.0/4.1 (ACTIVE/ACTIVE):
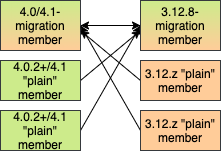
The diagram above outlines how you can perform a bidirectional migration between 3.12 and 4.0/4.1. In case you are using additional 3.12 or 4.0/4.1 clusters for Disaster Recovery (DR), please read the WAN Event Forwarding section for more information after reading this chapter. The process is simply a combination of the first two scenarios:
-
The first step is to set up the 3.12 and 4.0/4.1 clusters. You can also use existing clusters. The 3.12 cluster must have at least one "migration" member and the 4.0/4.1 cluster must also have at least one "migration" member. The "migration" member can also be a "lite" member while other "plain" members need not be. Making the "migration" member a "lite" member will also simplify further migration steps. Other "plain" members of the 3.12 cluster can be of any patch version and members of the 4.0/4.1 cluster should be at least 4.0.2 and at most 4.1 (any patch version). The exact ratio of "migration" and "plain" members depends on your environment. In some cases it will not be possible to mix members of different "types" (or versions, for example in PCF) and in those cases you can create a cluster comprised entirely out of "migration" members. In other cases, the exact ratio of member types depends on parameters such as the map and cache mutation rate on the source cluster, the WAN tuning parameters, the resources given to the cluster members, the load on the clusters which isn’t related to the migration process, if "migration" members are lite members or not and many more. A good rule of thumb is starting with the same number of "migration" members as the number of members which are usually involved in WAN replication (if you were already using WAN replication to replicate data between different clusters) or to simply use an equal number of "migration" and "plain" members and then decrease the number of "migration" members if testing the migration scenario shows that the decreased number can handle the migration load.
-
Setup WAN replication between the two clusters. As always, this can be done using static configuration and can be added dynamically. The key point is that both clusters need to replicate only to the "migration" members and not to the "plain" ones as they are unable to process messages from the members of another major version. Other than that, the WAN replication configuration is the same as any other regular WAN replication towards clusters of the same major version and no special configuration is needed.
-
After the clusters have been started and WAN replication has been added, you can use WAN sync for
IMapor wait until enough entries have been replicated in case ofIMaporICache. You can check if your map data is in sync by using merkle tree sync with the caveat that in some edge cases, the merkle tree consistency check may indicate that the clusters are out-of-sync while in reality they are actually in-sync. In other cases, once WAN sync completes successfully and if there are no errors, the map data should be synchronized. See Limitations and Known Issues section for more information when using merkle trees for consistency checks. -
After enough data has been replicated, you can shut down either of the clusters and afterwards shut down the remaining "migration" members or do a rolling restart of these members to "plain" members. If any of the clusters that you are keeping is comprised entirely out of "migration" members, you will need to do a rolling restart of the entire cluster (for example, when migrating in PCF).
WAN Event Forwarding:

Finally, we show how clusters of different major versions can be linked so that you can form complex topologies with WAN replication. The key restrictions that you need to keep in mind when combining are as follows:
-
If you are connecting members of different major versions, the recipient/target of the connection must be a "migration" member and not a "plain" member.
-
If a cluster contains a "migration" member, it may also contain "plain" members but with the added restriction that 4.x "plain" members should be at least 4.0.2 and at most 4.1 (any patch version). The 3.x "plain" members can be of any patch version. Once migration has finished and "migration" members have been shut down, this restriction is lifted.
-
If the cluster is a source/active/sender cluster replicating towards another cluster of another major version, the source cluster must be of the minor versions 3.12, 4.0 or 4.1. The patch level is irrelevant, unless the source cluster is also a target cluster for another WAN replication, where must adhere to the first two rules.
In case you were using an additional cluster for disaster recovery, you will need to set up WAN event forwarding from the migration target cluster to a new DR cluster and only after the migration process has finished may you shut down the source cluster and its' DR cluster. For example, see the following image for an example setup when migrating from 3.12 to 4.0/4.1 with additional DR clusters.
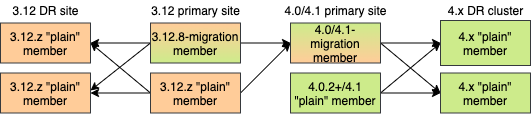
In the example above, once the migration is complete, you may shut down the 3.12 DR and primary sites.
Limitations and Known Issues
The solution is limited to IMap and ICache
Since we’re relying on WAN replication for migration, the data migration is restricted to migrating IMap and ICache data. In addition to this, IMap WAN replication supports WAN sync while ICache doesn’t.
The "migration" member needs to be able to deserialize and serialize all the received keys and values:
Since the serialized format of some classes changed between major versions,
we need to deserialize and re-serialize every key and value received from
a member from another major version. Otherwise, we might end up with two entries
in an IMap for the exact same key or we might not remove an entry even though
it was deleted on the source/active cluster. This is the task of the "migration" member
and it means that this member needs to have the class definition for all keys and values
received from the clusters of another major version. On the other hand, for entries received
from a cluster of the same major version, we don’t need to go through this process as we are
sure that the serialized format hasn’t changed. This saves us from spending processing time
and creating more litter for the GC to clean up.
Issues when replicating keys and values of specific classes:
Hazelcast 4.0 introduced the support for serializing some additional JDK classes with a predicatable serialized format:
-
CopyOnWriteArrayList -
HashMap,ConcurrentSkipListMap,ConcurrentHashMap,LinkedHashMap,TreeMap -
HashSet,TreeSet,LinkedHashSet,CopyOnWriteArraySet,ConcurrentSkipListSet -
ArrayDeque,LinkedBlockingDeque,LinkedBlockingQueue,ArrayBlockingQueue,PriorityBlockingQueue,PriorityQueue,DelayQueue,SynchronousQueue,LinkedTransferQueue -
UUID -
AbstractMap.SimpleEntry,AbstractMap.SimpleImmutableEntry
Hazelcast 3.x still may serialize some of these classes but only if
they support Java Serialization. That means, if you use instances of
these classes as keys or values in an IMap, you have to be sure the
class can be serialized by Hazelcast 3.x as well. Otherwise, adding the
key/value into the IMap may fail, either when something like map.put
is invoked on the 3.x cluster or when such a key/value is replicated over WAN from a 4.x cluster.
Regardless, we would like to discourage the usage of these classes on a 3.x cluster.
The output of Java serialization even for classes supporting it can be very unpredictable
and can depend on the internals of the instance which are usually ignored
(such as loadFactor for HashMap) or can even depend on the internals which are not under your control,
such as when serializing ArrayBlockingQueue. Because of this, if you use these classes as keys
in an IMap, you may end up with multiple entries for a seemingly same instance, e.g., two HashMap instances
equal as reported by equals are serialized as two different keys.
Issues when using merkle trees and keys and values of specific classes:
The serialized format of some classes changed between 3.12 and 4.0/4.1 and merkle trees may report that there are differences between two IMaps while in fact there is none. For WAN sync using merkle trees, this means the source cluster might transmit more entries than what is necessary to bring the two IMaps in-sync. This is not a correctness issue, and the IMaps should end up with the same contents. On the other hand, a "consistency check" might always report that the two IMaps are out-of-sync while in fact the contents of the IMaps are identical. Some examples of classes that exhibit this behavior when used as keys or values are as follows:
-
non-ascii
Strings and emojis -
HashMap,ConcurrentSkipListMap,ConcurrentHashMap,LinkedHashMap,TreeMap -
HashSet,TreeSet,LinkedHashSet, `CopyOnWriteArraySet,ConcurrentSkipListSet -
ArrayDeque,LinkedBlockingDeque,LinkedBlockingQueue,ArrayBlockingQueue,PriorityBlockingQueue,PriorityQueue,DelayQueue,SynchronousQueue,LinkedTransferQueue -
CopyOnWriteArrayList,ArrayList,LinkedList -
Class -
Date -
BigInteger,BigDecimal -
Object[],Enum`s, `UUID -
AbstractMap.SimpleEntry,AbstractMap.SimpleImmutableEntry.
Cannot use custom merge policies based on 3.x API:
WAN replication uses merge policies to apply a change on a target cluster entry. The merge policy is configured in the source cluster and it is transferred with each WAN event batch.
In Hazelcast 3.12, there were two different ways in which
you can configure a merge policy - data structure specific and data structure agnostic.
The data structure specific interfaces are com.hazelcast.map.merge.MapMergePolicy and
com.hazelcast.cache.CacheMergePolicy while the data structure agnostic interface is com.hazelcast.spi.merge.SplitBrainMergePolicy.
Both ways basically provide the same out-of-the-box policies as well as a way to implement user-defined
custom merge policies. The only difference is that data structure specific merge policies cannot
be shared between different data structure types such as IMap and ICache, while
the data structure agnostic merge policy can usually be shared between all data structures.
In Hazelcast 4.0, we removed the data structure specific merge policies.
To increase the ease-of-use, 4.0 "migration" members can still receive
the out-of-the-box data structure specific merge policies, such as com.hazelcast.map.merge.PassThroughMergePolicy, com.hazelcast.map.merge.PutIfAbsentMapMergePolicy
and com.hazelcast.cache.merge.PassThroughCacheMergePolicy, and it will "translate" these
merge policies into the corresponding out-of-the-box data structure agnostic merge policies.
The only limitation that applies here is that the "migration" member cannot interpret
custom, user-defined, data structure specific merge policies. If you are using such a merge policy,
you will need to switch to using a custom, user-defined, data structure agnostic merge policy
based on the com.hazelcast.spi.merge.SplitBrainMergePolicy interface, which should be simple enough.
Client Migration
With Hazelcast 4.0, in addition to all of the serialization changes done on the member side, there have been many changes in how the client connects and interacts with the cluster. On top of this, Hazelcast 4.0 introduced new features not available in 3.x and removed some features that were present in 3.x. Because of these changes it is not possible to maintain the "illusion" of connecting to a 4.x cluster with a 3.x member.
The general suggestion on approaching the migration of clients between 3.x and 4.x clusters is that the 3.x clients should stay connected to the 3.12 cluster and the 4.x clients should stay connected to the 4.0/4.1 cluster. The migration tool ensures that the data between 3.12 and 4.0/4.1 members is in-sync. You can then gradually transfer applications from the 3.x clients to applications using 4.x clients. After all applications are using the 4.x clients and reading/writing data from/to the 4.0/4.1 members, the 3.12 cluster and the 3.x clients can be shut down.
The same suggestion applies when migrating back from 4.0/4.1 to 3.12, only with the versions reversed.
Upgrading to Hazelcast IMDG 4.0
This section provides the guidelines for you when migrating to Hazelcast IMDG 4.0
Upgrading to 4.0 from Prior Versions (3.x)
IMDG 4.0 is a major version release. The last major version release was over five years ago. Major releases allow us to break compatibility in the wire protocols and API, as well as removing the previously deprecated API.
As breaking changes have been made to the client and cluster member protocols, it is not possible to perform any in-place or rolling upgrade from a running IMDG 3.x cluster to IMDG 4.x. The only way to upgrade to IMDG 4.x is to completely shutdown the cluster.
| There is a migration tool that allows upgrading specifically 3.12 to 4.0 or 4.1. See the above section. |
Removal of Hazelcast Client Module
-
The
hazelcast-clientmodule has been merged into the core module: All the classes in thehazelcast-clientmodule have been moved tohazelcast.hazelcast-client.jarwill not be created anymore. -
Also the
com.hazelcast.clientJava module is not used anymore. All classes are now available within thecom.hazelcast.coremodule.
JCache default Caching Provider
The default CachingProvider is the client-side CachingProvider. In order to select the
member-side CachingProvider, you can specify the member-side CachingProvider by defining
the Hazelcast property hazelcast.jcache.provider.type. See the Configuring JCache Provider section for more details.
Removal of User Defined Services
Hazelcast IMDG’s public SPI (Service Provider Interface) which was known as User Defined Service has been removed. It was not simple enough and backwards compatibility was broken. A new and clearly defined SPI may be developed in the future if there is enough interest. The removed SPI’s classes will be kept to be used internally.
Changes in Client Connection Retry Mechanism
-
The
connection-attempt-periodandconnection-attempt-limitconfiguration have been removed. Instead, the elements ofconnection-retryare now used. See the clients:java.adoc#configuring-client-connection-retry for the usage of those new elements.
Increasing the Member/Client Thread Counts
If there are 20 or more processors detected, the Hazelcast member by default starts 4+4 (4 input and 4 output) I/O threads. This is to increase out of the box performance on faster machines because often (especially the cache with caching situations) the performance is I/O bound and having some extra cores available for I/O can make a significant difference. If less than 20 cores are detected, 3+3 IO threads are used and the behavior remains the same as Hazelcast IMDG 3.x series.
A smart client, by default, gets 3+3 (3 input and 3 output) I/O threads to speed up the performance. Before Hazelcast IMDG 4.0, this was 1+1. However, the client I/O can become a bottleneck with too few threads. If TLS/SSL is enabled, then by default a smart client makes use of 3+3 I/O threads which was already the case with previous versions.
There is a new performance feature in Hazelcast IMDG 4.0 called
thread overcommit. By default, Hazelcast creates more
threads than it has cores, e.g., on a 20 cores machine it creates 28 threads;
20 threads for the partition operations
and 4+4 threads for I/O. In case of a typical caching usage (get/put/set, etc.)
having too many threads can cause a performance
degradation due to increased context switching. So there is
a new option called hazelcast.operation.thread.overcommit.
If this property is set to true, i.e., -Dhazelcast.operation.thread.overcommit=true,
which is the default, Hazelcast uses the old style thread
configuration where there are more threads than cores. If set to false,
the number of partition threads plus the I/O threads will be equal to the core count.
It depends on the environment if this gives a performance boost or not.
In some environments it can give a significant boost
and in some it will give a significant loss; it is best to benchmark
for your specific situation. If you are doing lots of queries or other tasks
which are CPU-bound, e.g aggregations, you probably want to have as many cores available to partition
operations as possible.
See the Threading Model section for more information on Hazelcast IMDG’s threading model.
Optimizing for Single Threaded Usages
A write-through optimization has been performed. This helps to reduce the latency in case of single threaded usages.
Normally, when a request is made, the request is handed over the I/O system where an I/O thread takes care of sending it over the wire. This is great for throughput, but in case of single threaded setups, it adds to the latency and therefore it reduces the throughput because threads need to be notified.
With this release, Hazelcast IMDG detects the single threaded usage and tries to write through to the socket directly instead of handing it over to the I/O thread; this optimization is called "write-through".
This technique is being applied on the client, but also on the member. We have something similar when responses are received: normally a response is processed by the response thread, but in case of a single threaded usage, the response is processed on the I/O thread so we can remove a thread notification and therefore get higher throughput.
Both the write-through and response-through are enabled by default. If Hazelcast IMDG detects that there are many active threads, response- and write-through are disabled so it won’t cause a performance degradation.
Renaming GroupProperty
The GroupProperty class that defines the Hazelcast system properties
has been renamed as ClusterProperty to align with the change mentioned here.
Removing Deprecated Client Configurations
The following methods of ClientConfig have been refactored:
-
addNearCacheConfig(String, NearCacheConfig)→addNearCacheConfig(NearCacheConfig) -
setSmartRouting(boolean)→getNetworkConfig().setSmartRouting(boolean); -
getSocketInterceptorConfig()→getNetworkConfig().getSocketInterceptorConfig(); -
setSocketInterceptorConfig(SocketInterceptorConfig)→getNetworkConfig().setSocketInterceptorConfig(SocketInterceptorConfig); -
getConnectionTimeout()→getNetworkConfig().getConnectionTimeout(); -
setConnectionTimeout(int)→getNetworkConfig().setConnectionTimeout(int); -
addAddress(String)→getNetworkConfig().addAddress(String); -
getAddresses()→getNetworkConfig().getAddresses(); -
setAddresses(List)→getNetworkConfig().setAddresses(List); -
isRedoOperation()→getNetworkConfig().isRedoOperation(); -
setRedoOperation(boolean)→getNetworkConfig().setRedoOperation(boolean); -
getSocketOptions()→getNetworkConfig().getSocketOptions(); -
setSocketOptions()→getNetworkConfig().setSocketOptions(SocketOptions); -
setSocketOptions()→getNetworkConfig().setSocketOptions(SocketOptions); -
getNetworkConfig().setAwsConfig(new ClientAwsConfig());→getNetworkConfig().setAwsConfig(new AwsConfig());
Also the ClientAwsConfig class has been renamed as AwsConfig.
The naming for the declarative configuration elements have not been changed. See the Release Notes for new/removed configuration features.
See the following table for the before/after configuration samples.
Before IMDG 4.0 |
After IMDG 4.0 |
Adding Near Cache |
|
|
|
Programmatic Configuration |
|
|
|
Changes in Index Configuration
In order to support further extensibility of Hazelcast, index configuration has been refactored.
Index type is now defined through the IndexType enumeration
instead of the boolean flag: ordered index is now referred to as
IndexType.SORTED, unordered as IndexType.HASH.
In composite indexes, index parts are now defined as a list of strings instead of a single string with comma-separated values.
With these changes, the following configuration parameters have been renamed:
Programmatic configuration objects and methods:
-
MapIndexConfig→IndexConfig -
MapConfig.getMapIndexConfig→MapConfig.getIndexConfig -
MapConfig.setMapIndexConfig→MapConfig.setIndexConfig -
MapConfig.addMapIndexConfig→MapConfig.addIndexConfig -
IMap.addIndex(String, boolean)→IMap.addIndex(IndexConfig)
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
Programmatic Configuration |
|
|
|
Declarative Configuration |
|
|
|
Dynamic Index Create |
|
|
|
Changes in Custom Attributes
Custom attributes are referenced in predicates, queries and indexes. Some improvements have been performed in Hazelcast’s query engine and one of the results is the change in custom attribute configurations.
With this change, the following configuration parameters have been renamed:
Declarative configuration elements:
-
extractor→extractor-class-name
Programmatic configuration objects and methods:
-
MapAttributeConfig→AttributeConfig -
setExtractor()→setExtractorClassName() -
addMapAttributeConfig()→addAttributeConfig()
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
Programmatic Configuration |
|
|
|
Declarative Configuration |
|
|
|
Also, some custom query attribute classes were previously abstract classes with one abstract method. They have been converted into functional interfaces:
Before IMDG 4.0 |
After IMDG 4.0 |
Implementing |
|
|
|
Removal of MapReduce
MapReduce API has been removed, which was deprecated since Hazelcast IMDG 3.8. Instead, you can use the Aggregations on top of Query infrastructure and the Hazelcast Jet distributed computing platform as its successors and replacements.
See the following table for the before(MapReduce)/after(Hazelcast Jet) word count sample.
Before IMDG 4.0 (MapReduce) |
After IMDG 4.0 (Hazelcast Jet) |
Word Count Sample |
|
|
|
See the Jet Code Samples for a full insight.
Refactoring of Migration Listener
The MigrationListener API has been refactored.
With this change, an event is published when a new
migration process starts and another event when migration
is completed. These events include statistics
about the migration process including the start time,
planned migration count, completed migration count, etc.
Additionally, a migration event is published on each replica migration, both for primary and backup replica migrations. This event includes the partition ID, replica index and migration progress statistics.
Before IMDG 4.0, the following were the events listened by MigrationListener:
-
migrationStarted -
migrationCompleted -
migrationFailed
After IMDG 4.0, we have the following events instead:
-
migrationStarted -
migrationFinished -
replicaMigrationCompleted -
replicaMigrationFailed
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
Implementing a Migration Listener |
|
|
|
See the MigrationListener Javadoc for a full insight.
Defaulting to OpenSSL
Hazelcast IMDG defaults to use OpenSSL when:
-
when you use TLS/SSL and Hazelcast IMDG detects some OpenSSL capabilities
-
the Java version is less than 11
-
no explicit SSLEngineFactory is configured.
Changes in Security Configurations
Replacing group by Simple Cluster Name Configuration
The GroupConfig class has been removed. Both the client and member configurations have
the GroupConfig (or <group> in XML) replaced by a simple cluster name configuration.
The password part from the GroupConfig which was already deprecated is removed now.
See the following table for the before/after sample configurations.
Before IMDG 4.0 |
After IMDG 4.0 |
Declarative Configuration |
|
|
|
Programmatic Configuration |
|
|
|
Member Authentication and Identity Configuration
Hazelcast IMDG 4.0 replaces the <member-credentials-factory>, <member-login-modules> and
<client-login-modules> configuration by references to security realms.
The security realms is a new abstraction in the security configuration of Hazelcast members.
It defines the security configuration independently on the configuration
part where the security is used. The component requesting security just references
the security realm name.
See the following table for the before/after sample configurations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Client Identity Configuration
The <credentials> configuration is not supported
anymore in the client security configuration.
Existing <credentials-factory> configuration allows
to fully replace the credentials as it is more flexible.
There are also new <username-password> and <token>
configuration elements which simplify the migration.
See the following table for the before/after sample configurations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
JAAS Authentication Cleanups
Introducing New Principal Types
The ClusterPrincipal class representing an authenticated user within the JAAS Subject
has been replaced by three different principal types:
-
ClusterIdentityPrincipal -
ClusterRolePrincipal -
ClusterEndpointPrincipal
All these new principal types share the HazelcastPrincipal interface so
it is simple to get or remove them all from the subject.
With this change, the Credentials object is not referenced from
the principals anymore.
Also, DefaultPermissionPolicy which was consuming ClusterPrincipal
and also reading the endpoint address from it works with the new
ClusterRolePrincipals and ClusterEndpointPrincipals principal types.
See the following table for the before/after sample IPermissionPolicy implementations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Changes in ClusterLoginModule
ClusterLoginModule in Hazelcast IMDG 3.x contained four
abstract methods to alter the behavior of LoginModule:
-
onLogin -
onCommit -
onAbort -
onLogout
The login module was retrieving Credentials and
using it to create the ClusterPrincipal back then.
In Hazelcast IMDG 4.0, only onLogin is abstract.
Others now have empty implementations. The login module creates
ClusterEndpointPrincipal automatically and adds it to the Subject.
The getName() abstract method has been added. It is used for
constructing ClusterIdentityPrincipal. The addRole(String) method
can be called by the child implementations to add ClusterRolePrincipals
with the given name.
Also, ClusterLoginModule introduces three login module options (boolean),
which allows skipping principals of a given type to the JAAS Subject.
It allows, for instance, to have just one ClusterIdentityPrincipal
in the Subject even if there are more login modules in the chain. These
options are:
-
skipIdentity -
skipRole -
skipEndpoint.
See the following table for the before/after sample implementations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Changes in Credentials for Client Protocol
In Hazelcast IMDG 3.x, the custom credentials coming through
the client protocol was always automatically deserialized. To
avoid this, the Credentials interface has been redesigned in
Hazelcast IMDG 4.0 to contain only the getName()
(renamed from getPrincipal()) method.
The endpoint handling has been moved out of the interface.
Now, Credentials has two new subinterfaces:
-
PasswordCredentials: The existingUsernamePasswordCredentialsclass is the default implementation. -
TokenCredentials: The newSimpleTokenCredentialsclass has been introduced to implement it.
TokenCredentials is just a holder for byte array, and
the authentication implementations themselves, i.e., custom LoginModules,
are responsible for the data deserialization when needed.
The data from client authentication message is not deserialized by Hazelcast members
anymore. For standard authentication, UsernamePasswordCredentials is constructed.
For custom authentication, SimpleTokenCredentials is constructed.
If the original Credentials object is not a PasswordCredentials
or TokenCredentials instance, then it can be deserialized manually.
However, the deserialization during authentication remains a dangerous
operation and should be avoided.
See the following table for the before/after sample implementations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Credentials serialization and deserialization in the member protocol
has not been changed.
|
Changes in JAAS Callbacks
In Hazelcast IMDG 3.x, the CallbackHandler implementation ClusterCallbackHandler
was only able to work with Hazelcast’s CredentialsCallback.
In Hazelcast IMDG 4.0, it also works with the standard Java Callback implementations
NameCallback and PasswordCallback.
DefaultLoginModule was using the login module options to retrieve the
member’s Config object. Now, custom Callback types have been
implemented which can be used to retrieve additional data required for
the authentication.
List of the supported Callbacks in Hazelcast IMDG 4.0:
-
javax.security.auth.callback.NameCallback -
javax.security.auth.callback.PasswordCallback -
com.hazelcast.security.CredentialsCallback(provides access to the incomingCredentialsinstance) -
com.hazelcast.security.EndpointCallback(allows retrieving the remote host address, it’s a replacement forCredentials.getEndpoint()in Hazelcast IMDG 3.x) -
com.hazelcast.security.ConfigCallback(allows retrieving member’sConfigobject) -
com.hazelcast.security.SerializationServiceCallback(provides access to HazelcastSerializationService) -
com.hazelcast.security.ClusterNameCallback(provides access to Hazelcast cluster name sent by the connecting party)
Renaming Quorum as Split Brain Protection
Both in the API/code samples and documentation, the term "quorum" has been replaced by "split-brain protection".
With this change, the following configuration parameters have been renamed:
Declarative configuration elements:
-
quorum→split-brain-protection -
quorum-size→minimum-cluster-size -
quorum-ref→split-brain-protection-ref -
quorum-type→protect-on -
probabilistic-quorum→probabilistic-split-brain-protection -
recently-active-quorum→recently-active-split-brain-protection -
quorum-function-class-name→split-brain-protection-function-class-name -
quorum-listeners→split-brain-protection-listeners
Programmatic configuration objects and methods:
-
QuorumConfig→SplitBrainProtectionConfig -
QuorumConfig.setSize()→SplitBrainProtectionConfig.setMinimumClusterSize() -
QuorumConfig.setType()→SplitBrainProtectionConfig.setProtectOn() -
QuorumListenerConfig→SplitBrainProtectionListenerConfig -
QuorumEvent→SplitBrainProtectionEvent -
QuorumService→SplitBrainProtectionService -
QuorumService.getQuorum()→SplitBrainProtectionService.getSplitBrainProtection() -
isPresent()→hasMinimumSize() -
setQuorumName()→setSplitBrainProtectionName() -
addQuorumConfig()→addSplitBrainProtectionConfig() -
newProbabilisticQuorumConfigBuilder()→newProbabilisticSplitBrainProtectionConfigBuilder() -
newRecentlyActiveQuorumConfigBuilder()→newRecentlyActiveSplitBrainProtectionConfigBuilder()
See the following table for a before/after sample.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
See the Split-Brain Protection section for more information on network partitioning.
Renaming getID to getClassId in IdentifiedDataSerializable
The getId() method of the IdentifiedDataSerializable interface
is a method with a common name, meaning a naming conflict would happen frequently.
For example, database entities also have a getId() method.
Therefore, it has been renamed as getClassId().
See the following table showing the interface code before and after IMDG 4.0.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
See here for more information on IdentifiedDataSerializable.
Introducing Lambda Friendly Interfaces
Entry Processor
The EntryBackupProcessor interface has been removed in favor
of EntryProcessor which now defines how the entries will be processed
both on the primary and the backup replicas.
Because of this, the AbstractEntryProcessor interface has been removed.
This should make writing entry processors more lambda friendly.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
This should cover most cases. If you need to define a custom
backup entry processor, you can override the EntryProcessor#getBackupProcessor method.
map.executeOnKey(key, new EntryProcessor<Object, Object, Object>() {
@Override
public Object process(Entry<Object, Object> entry) {
// process primary entry
}
private Object processBackupEntry(Entry<Object, Object> backupEntry) {
// process backup entry
}
@Nullable
@Override
public EntryProcessor<Object, Object, Object> getBackupProcessor() {
return this::processBackupEntry;
}
});Functional and Serializable Interfaces
Introduces interfaces with single abstract method which declares a
checked exception. The interfaces are also Serializable and can be
readily used when providing a lambda which is then serialized.
The Projection class was an abstract interface for historical reasons. It has been turned into a functional interface so it’s more lambda-friendly.
See the following table for the before/after sample implementations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Expanding Nullable/Nonnull Annotations
The APIs of the distributed data structures have been made cleaner
by adding Nullable and Nonnull annotations, and
their API documentation have been improved:
-
Now, it is obvious when looking at the API where
nullis allowed and where it is not. -
Some methods were throwing
NullPointerExceptionwhile others were throwingIllegalArgumentException. Now the behavior is aligned and an unexpectednullargument results in aNullPointerExceptionbeing thrown. -
Some methods actually allowed
nullbut there was no indication that they did. -
A method when used on the member would accept
nulland have some behavior accordingly while, on the client, the method would throw aNullPointerException. Now, the behavior of the member and client have been aligned.
The data structures and interfaces enhanced in this sense are listed below:
-
IQueue,ISet,IList -
IMap,MultiMap,ReplicatedMap -
Cluster -
ITopic -
Ringbuffer -
ScheduledExecutor
Removal of ICompletableFuture
In Hazelcast IMDG 3.x series, com.hazelcast.core.ICompletableFuture was
introduced to enable reactive programming style. ICompletableFuture was
intended as a temporary, JDK 6 compatible replacement for java.util.concurrent.CompletableFuture
that was introduced in Java 8. Since Hazelcast 4.0 requires Java 8, the user-facing
asynchronous Hazelcast API methods now have their return type changed from
ICompletableFuture to Java 8’s java.util.concurrent.CompletionStage.
Dependent computation stages registered using default async methods which do not
accept an explicit Executor argument (such as thenAcceptAsync, whenCompleteAsync etc)
are executed by the java.util.concurrent.ForkJoinPool#commonPool() (unless it does not
support a parallelism level of at least two, in which case, a new Thread is created to
run each task).
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
WAN Replication Configuration Changes
Previously, Configuring WAN replication was problematic:
-
You needed to specify the fully qualified class name of the WAN implementation that should be used. In most cases, this was the built-in Hazelcast IMDG Enterprise Edition (EE) implementation.
-
There were various configuration options, some of which were present as Java class instance fields or XML child nodes and attributes while others were present in a properties list. The issue with the property list is that there was no checking for typos, no documentation and no IDE help.
-
If you wanted to use a custom WAN publisher SPI implementation, some configuration options did not make sense as they were tied to our implementation, e.g., WAN queue size.
-
It was verbose.
The tag which was supposed to cover both cases, using the built-in Hazelcast EE implementation and a
custom WAN replication implementation (wan-publisher or WanPublisherConfig), has been separated into
two configuration elements/classes to be used for built-in and custom WAN publishers:
-
batch-publisher(declarative configuration) orWanBatchPublisherConfig(programmatic configuration) -
custom-publisher(declarative configuration) orWanCustomPublisherConfig(programmatic configuration)
This means, if you’re using the Hazelcast built-in WAN replication, the new configuration element
is batch-publisher or WanBatchPublisherConfig.
If you’re using a custom WAN replication implementation, the new configuration element is
custom-publisher or WanCustomPublisherConfig.
Additionally, the group password has been removed from the configuration and now only the cluster name is checked when connecting to the target cluster. This has been done to align the behavior with members forming a single cluster, where members with different passwords but with the same cluster name (previously group name) could form a cluster.
See the following table for the before/after built-in WAN publisher examples:
Before IMDG 4.0 |
After IMDG 4.0 |
Declarative Configuration |
|
|
|
Programmatic Configuration |
|
|
|
See the following table for the before/after custom WAN publisher examples:
Before IMDG 4.0 |
After IMDG 4.0 |
Declarative Configuration |
|
|
|
Programmatic Configuration |
|
|
|
See the here for more information on WAN Replication.
WAN Replication SPI Changes
In IMDG 3.x series, the WAN publisher SPI allowed you to plug into the lifecycle of a map/cache entry and replicate the updates to another system. For example, you might implement replication to Kafka or some JMS queue or even write out map and cache event changes to a log on disk. The SPI was not very intuitive though:
-
It was not clear which interface needed to be implemented (
WanPublishervs.WanReplicationEndpoint). -
You had to implement different interfaces, depending on whether you were using Hazelcast IMDG Open Source or Enterprise edition.
-
There were cases of leaking internals which don’t make sense for some custom implementations.
-
There were unused methods in the public SPI.
In Hazelcast IMDG 4.0, we have provided a new and cleaner WAN publisher SPI. You only need to
implement a single interface: com.hazelcast.wan.WanPublisher. This implementation can
then be set in the WAN replication configuration and be used with both Hazelcast Open Source and
Enterprise editions.
Predicate API Cleanups
The following refactors and cleanups have been performed on the public Predicate related API:
-
Moved the following classes from the
com.hazelcast.querypackage tocom.hazelcast.query.impl.predicates:-
IndexAwarePredicate -
VisitablePredicate -
SqlPredicate/Parser -
TruePredicate
-
-
Moved the
FalsePredicateandSkipIndexPredicateclasses to thecom.hazelcast.query.impl.predicatespackage. -
Converted
PagingPredicateandPartitionPredicateto interfaces and addedPagingPredicateImplandPartitionPredicateImplto thecom.hazelcast.query.impl.predicatepackage. -
Converted
PredicateBuilderandEntryObjectto interfaces (and madeEntryObjecta nested interface inPredicateBuilder) and addedPredicateBuilderImplto thecom.hazelcast.query.impl.predicatespackage. -
The public API classes/interfaces no longer extend
IndexAwarePredicate/VisitablePredicate; this dependency has been moved to theimplclasses. -
Introduced the new factory methods in
Predicates:-
newPredicateBuilder() -
sql() -
pagingPredicate() -
partitionPredicate()
-
Consequently, the public Predicate API now provides only interfaces (Predicate,
PagingPredicate and PartitionPredicate) with no dependencies on any internal APIs.
See the Distributed Query chapter for more information on predicates.
Changing the UUID String Type to UUID
Some public APIs that return UUID strings have been changed to return UUID.
These changes include getUuid() method of the Endpoint interface,
getTxnId() method of the TransactionContext interface,
return values of the listener registrations and registrationId parameters for the methods
that de-register the listeners.
See the following table for the before/after sample implementations.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Removal of Deprecated Concurrency API Implementations
After introduction of CP Subsystem in Hazelcast IMDG 3.12,
legacy implementations of the distributed concurrency APIs, e.g., ILock and IAtomicLong,
had been deprecated.
In IMDG 4.0, these deprecated implementations and additionally
ILock and ICondition interfaces are completely removed.
Differently from Hazelcast IMDG 3.12, CP Subsystem received an unsafe operation mode in IMDG 4.0 which provides weaker consistency guarantees similar to former implementations in Hazelcast IMDG 3.x series.
For more information, see the CP Subsystem section.
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Removal of Legacy Merge Policies
All legacy merge policies have been removed. Replacements of
legacies are under the com.hazelcast.spi.merge package.
These are the replacements for IMap and ICache:
Removed IMap Merge Policies and Their Replacements
-
com.hazelcast.map.merge.HigherHitsMapMergePolicy→com.hazelcast.spi.merge.HigherHitsMergePolicy -
com.hazelcast.map.merge.LatestUpdateMapMergePolicy→com.hazelcast.spi.merge.LatestUpdateMergePolicy -
com.hazelcast.map.merge.PassThroughMergePolicy→com.hazelcast.spi.merge.PassThroughMergePolicy -
com.hazelcast.map.merge.PutIfAbsentMapMergePolicy→com.hazelcast.spi.merge.PutIfAbsentMergePolicy
Removed ICache Merge Policies and Their Replacements
-
com.hazelcast.cache.merge.HigherHitsCacheMergePolicy→com.hazelcast.spi.merge.HigherHitsMergePolicy -
com.hazelcast.cache.merge.LatestAccessCacheMergePolicy→com.hazelcast.spi.merge.LatestAccessMergePolicy -
com.hazelcast.cache.merge.PassThroughCacheMergePolicy→com.hazelcast.spi.merge.PassThroughMergePolicy -
com.hazelcast.cache.merge.PutIfAbsentCacheMergePolicy→com.hazelcast.spi.merge.PutIfAbsentMergePolicy
Moreover, the setMergePolicy/getMergePolicy methods have been
removed from MapConfig, ReplicatedMapConfig and CacheConfig.
They have been replaced by the setMergePolicyConfig/getMergePolicyConfig methods.
The merge-policy declarative configuration element that
has been used in the older IMDG versions still can be used:
<merge-policy batch-size="100">LatestAccessMergePolicy</merge-policy>See here for more information on configuring merge policies.
Changes in AWS Configuration
AWS programmatic configuration has been merged with a more universal configuration infrastructure common to all cloud providers. The declarative configuration remains unchanged. See here for more information on configuring Hazelcast IMDG on AWS.
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Removal of Deprecated System Properties
The following deprecated cluster properties were removed:
-
hazelcast.rest.enabled -
hazelcast.memcache.enabled -
hazelcast.http.healthcheck.enabled
Please see the Using the REST Endpoint Groups section on how to configure Hazelcast instance to expose REST endpoints. Please see the the Health Check and Monitoring section on how to enable the health check. Please see the Memcache Client section on how to enable memcache client request listener service.
Removal of Deprecations in LoginModuleConfig
The following deprecated methods have been removed:
-
getImplementation(), replaced bygetClassName(). -
setImplementation(Object), replaced bysetClassName(String).
In declarative configuration class-name property should be used instead.
Removal of Deprecations in MultiMapConfig
The following deprecated methods have been removed:
-
getSyncBackupCount(), replaced bygetBackupCount(). -
setSyncBackupCount(int), replaced bysetBackupCount(int).
In declarative configuration backup-count property should be used instead.
See here for more information on configuring MultiMap.
Removal of Deprecations in PartitioningStrategyConfig
Misspelled setPartitionStrategy(PartitioningStrategy) has been removed,
setPartitioningStrategy(PartitioningStrategy) should be used instead.
See here for more information on configuring MultiMap.
Removal of Deprecations in ServiceConfig
The following deprecated methods have been removed:
-
getServiceImpl(), replaced bygetImplementation(). -
setServiceImpl(Object), replaced bysetImplementation(Object).
See the here
for ServiceConfigs Javadoc.
Removal of Deprecations in TransactionContext
Deprecated getXaResource() method has been removed. HazelcastInstance.getXAResource()
should be used instead.
See the here
for HazelcastInstances Javadoc.
Removal of Deprecations in DistributedObjectEvent
Deprecated getObjectId() method has been removed, getObjectName() should be used
instead.
See the here
for DistributedObjectEventss Javadoc.
Removal of Deprecated EntryListener-based Listener API in IMap
The following set of deprecated EntryListener-based listener API methods has been
removed:
-
addLocalEntryListener(EntryListener<K, V>) -
addLocalEntryListener(EntryListener<K, V>, Predicate<K, V>, boolean) -
addLocalEntryListener(EntryListener<K, V>, Predicate<K, V>, K, boolean) -
addEntryListener(EntryListener<K, V>, boolean) -
addEntryListener(EntryListener<K, V>, K, boolean)
The following MapListener-based methods should be used as replacements:
-
addLocalEntryListener(MapListener) -
addLocalEntryListener(MapListener, Predicate<K,V>, boolean) -
addLocalEntryListener(MapListener, Predicate<K,V>, K, boolean) -
addEntryListener(MapListener, boolean) -
addEntryListener(MapListener, K, boolean)
EntryListener-based listeners are still supported by the newer
MapListener-based API and declarative configuration.
Changes in IMap Eviction Configuration
There has been a simplification and improvement in the way of configuring the eviction for a map.
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Changes in IMap Custom Eviction Policy Configuration
There has been a simplification and improvement in the way of configuring the custom eviction policy for a map.
See the following table for the before/after samples.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Changes in EntryListenerConfig
Return type of the EntryListenerConfig.getImplementation()
method has been changed from EntryListener to MapListener.
See the following table for the before/after snippets.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Changes in REST Endpoints
The following REST endpoints have been changed:
-
/hazelcast/rest/mancenter/changeurlis removed -
All
/hazelcast/rest/mancenter/wan/*endpoints are renamed to/hazelcast/rest/wan/
The following REST endpoints now require cluster name and password as the first two URL-encoded parameters:
-
/hazelcast/rest/wan/sync/map -
/hazelcast/rest/wan/sync/allmaps -
/hazelcast/rest/wan/clearWanQueues -
/hazelcast/rest/wan/addWanConfig -
/hazelcast/rest/wan/pausePublisher -
/hazelcast/rest/wan/stopPublisher -
/hazelcast/rest/wan/resumePublisher -
/hazelcast/rest/wan/consistencyCheck/map
The output of the following endpoints has been changed to JSON:
-
/hazelcast/health/node-state -
/hazelcast/health/cluster-state -
/hazelcast/health/cluster-safe -
/hazelcast/health/migration-queue-size -
/hazelcast/health/cluster-size -
/hazelcast/health/ready -
/hazelcast/rest/cluster
Changes in the Diagnostics Configuration
By introducing the metrics system in Hazelcast IMDG 4.0, the metrics collected by Diagnostics and the metrics system is shared. This has come with the following changes of the system properties that configure diagnostics:
-
hazelcast.diagnostics.metric.levelis not available anymore. Collecting debug metrics can be enabled by setting thehazelcast.metrics.debug.enabledorhazelcast.client.metrics.debug.enabledsystem properties totruefor the members and clients respectively. -
hazelcast.diagnostics.metric.distributed.datastructuresis not anymore available since the data structure metrics are required for the other Metric Consumers. Therefore, they are collected by default and no need for enabling it for the diagnostics.
Changes in the Management Center Configuration
As Management Center now uses Hazelcast Java client for communication with the cluster,
all attributes and nested elements have been removed from programmatic, XML and YAML configurations
for Management Center, i.e., from ManagementCenterConfig class and management-center
configuration element, except for the scripting-enabled attribute.
The default value of scripting-enabled attribute is false, whereas in
Hazelcast 3.x it was enabled by default for Hazelcast Open Source.
A full example of settings available in the Management Center configuration now looks like the following:
<management-center scripting-enabled="true" />This has come with the following changes of the system properties that configure Management Center:
-
hazelcast.mc.url.change.enabledis not available anymore.
Changes in the Event Journal Configuration
Event journal configuration had been put as a top-level configuration element. With IMDG 4.0, this restriction has been removed; this means event journal configuration now can be part of both map and cache configurations. This eliminates additionally specifying the map /cache names on the event journal configuration to connect it to the map/cache configurations.
See the following table for the before/after snippets.
Before IMDG 4.0 |
After IMDG 4.0 |
|
|
Upgrading to Hazelcast IMDG 3.12.x
-
REST endpoint authentication: The authentication to REST endpoints has been changed in Hazelcast IMDG 3.12. Hazelcast IMDG 3.11.x checks group name and password, while 3.12 checks just the group name when security is disabled, and it uses the client login modules when the security is enabled.
-
Upgrading Cluster Version From IMDG 3.11 to 3.12: For the IMDG versions before 3.12, REST API could be enabled by using the
hazelcast.rest.enabledsystem property, which is deprecated now. IMDG 3.12 and newer versions introduce therest-apiconfiguration element along with REST endpoint groups. Therefore, a configuration change is needed specifically when performing a rolling member upgrade from IMDG 3.11 to 3.12.So, the steps listed in the above installation:rolling-upgrades.adoc#rolling-upgrade-procedure section should be as follows:
-
Shutdown the 3.11 member
-
Wait until all partition migrations are completed
-
Update the member with 3.12 binaries
-
Update the configuration (see below)
-
Start the member
For the 4th step ("Update the configuration"), the configuration should be updated as follows:
<hazelcast> ... <rest-api enabled="true"> <endpoint-group name="CLUSTER_WRITE" enabled="true"/> </rest-api> ... </hazelcast>See the Using the REST Endpoint Groups section for more information.
-
Upgrading from Hazelcast IMDG 3.10.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.9.x to 3.10.x and newer.
-
Starting with Hazelcast 3.10, split-brain recovery is supported for the data structures whose in-memory format is
NATIVE.
Upgrading from Hazelcast IMDG 3.9.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.9.x to 3.10.x and newer.
-
The system property based configuration for Ping Failure Detector is deprecated. Instead, use the elements to configure it, an example of which is shown below:
<hazelcast> <network> ... <failure-detector> <icmp enabled="true"> <timeout-milliseconds>1000</timeout-milliseconds> <fail-fast-on-startup>true</fail-fast-on-startup> <interval-milliseconds>1000</interval-milliseconds> <max-attempts>2</max-attempts> <parallel-mode>true</parallel-mode> <ttl>255</ttl> </icmp> </failure-detector> </network> ... </hazelcast>
Until Hazelcast IMDG 3.10, the configuration has been like the following:
<hazelcast>
...
<properties>
<property name="hazelcast.icmp.enabled">true</property>
<property name="hazelcast.icmp.parallel.mode">true</property>
<property name="hazelcast.icmp.timeout">1000</property>
<property name="hazelcast.icmp.max.attempts">3</property>
<property name="hazelcast.icmp.interval">1000</property>
<property name="hazelcast.icmp.ttl">0</property>
</properties>
...
</hazelcast>Upgrading to Hazelcast IMDG 3.8.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.7.x to 3.8.x and newer.
-
Introducing <wan-publisher> element: The configuration element
<target-cluster>has been replaced with the element<wan-publisher>in WAN replication configuration. -
WaitNotifyService interface has been renamed as OperationParker.
-
Synchronizing WAN Target Cluster: The URL for the related REST call has been changed from
http://member_ip:port/hazelcast/rest/wan/sync/maptohttp://member_ip:port/hazelcast/rest/mancenter/wan/sync/map. -
JCache usage: Due to a compatibility problem,CacheConfigserialization may not work if your member is 3.8.x where x < 5. You need to use the 3.8.5 or higher versions where the problem is fixed.
Upgrading to Hazelcast IMDG 3.7.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.6.x to 3.7.x and newer.
-
Important note about Hazelcast System Properties: Even Hazelcast has not been recommending the usage of
GroupProperties.javaclass while benefiting from system properties, there has been a change to inform to the users who have been using this class: the classGroupProperties.javahas been replaced byGroupProperty.java. In this new class, system properties are instances of the newly introducedHazelcastPropertyobject. You can access the names of these properties by calling thegetName()method ofHazelcastProperty. -
Removal of WanNoDelayReplication:
WanNoDelayReplicationimplementation of Hazelcast’s WAN Replication has been removed. You can still achieve this behavior by setting the batch size to1while configuring the WanBatchReplication. See the Defining WAN Replication section for more information. -
JCacheusage: Changes inJCacheimplementation which broke compatibility of 3.6.x clients to 3.7, 3.7.1, 3.7.2 cluster members and vice versa. 3.7, 3.7.1, 3.7.2 clients are also incompatible with 3.6.x cluster members. This issue only affects Java clients which useJCachefunctionality.You can use a compatibility option which can be used to ensure backwards compatibility with 3.6.x clients.
In order to upgrade a 3.6.x cluster and clients to 3.7.3 (or later), you need to use this compatibility option on either the member or the client side, depending on which one is upgraded first:
-
first upgrade your cluster members to 3.7.3, adding property
hazelcast.compatibility.3.6.client=trueto your configuration; when started with this property, cluster members are compatible with 3.6.x and 3.7.3+ clients but not with 3.7, 3.7.1, 3.7.2 clients. Once your cluster is upgraded, you may upgrade your applications to use client version 3.7.3+. -
upgrade your clients from 3.6.x to 3.7.3, adding property
hazelcast.compatibility.3.6.server=trueto your Hazelcast client configuration. A 3.7.3 client started with this compatibility option is compatible with 3.6.x and 3.7.3+ cluster members but incompatible with 3.7, 3.7.1, 3.7.2 cluster members. Once your clients are upgraded, you may then proceed to upgrade your cluster members to version 3.7.3 or later.You may use any of the supported ways as described in the System Properties section to configure the compatibility option. When done upgrading your cluster and clients, you may remove the compatibility property from your Hazelcast member configuration.
-
-
The
eviction-percentageandmin-eviction-check-milliselements are deprecated. They are ignored if configured, since the map eviction is based on the sampling of entries. See the Eviction Algorithm section for details.
Upgrading to Hazelcast IMDG 3.6.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.5.x to 3.6.x and newer.
-
Introducing new configuration options for WAN replication: WAN replication related system properties, which are configured on a per member basis, can now be configured per target cluster. The following system properties are no longer valid.
-
hazelcast.enterprise.wanrep.batch.size, see the Batch Size section. -
hazelcast.enterprise.wanrep.batchfrequency.seconds, see the Batch Maximum Delay section. -
hazelcast.enterprise.wanrep.optimeout.millis, see the Response Timeout section. -
hazelcast.enterprise.wanrep.queue.capacity, see the Queue Capacity section.
-
-
Removal of deprecated
getId()method: The methodgetId()in the interfaceDistributedObjecthas been removed. Please use thegetName()method instead. -
Change in the Custom Serialization in the C++ Client Distribution: Before, the method
getTypeId()was used to retrieve the ID of the object to be serialized. With this release, the methodgetHazelcastTypeId()is used and you give your object as a parameter to this new method. Also,getTypeId()was used in your custom serializer class; it has been renamed togetHazelcastTypeId(), too. -
The
LOCALtransaction type has been deprecated. UseONE_PHASEfor the Hazelcast IMDG releases 3.6 and higher.
Upgrading to Hazelcast IMDG 3.5.x
This section provides information to be considered when upgrading from Hazelcast IMDG 3.4.x to 3.5.x and newer.
-
Introducing the
spring-awareelement: Hazelcast usedSpringManagedContextto scanSpringAwareannotations by default. This was causing some performance overhead for the users who do not useSpringAware. With this release,SpringAwareannotations are disabled by default. By introducing thespring-awareelement, it is possible to enable it by adding the<hz:spring-aware />tag to the configuration. See the Spring Integration section.
Upgrading to Hazelcast IMDG 3.x
This section provides information to be considered when upgrading from Hazelcast IMDG 2.x to 3.x.
-
Removal of deprecated static methods: The static methods of Hazelcast class reaching Hazelcast data components have been removed. The functionality of these methods can be reached from the
HazelcastInstanceinterface. You should replace the following:Map<Integer, String> customers = Hazelcast.getMap( "customers" );with
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(); // or if you already started an instance named "instance1" // HazelcastInstance hazelcastInstance = Hazelcast.getHazelcastInstanceByName( "instance1" ); Map<Integer, String> customers = hazelcastInstance.getMap( "customers" ); -
Renaming "instance" to "distributed object": There were confusions about the term "instance"; it was used for both the cluster members and distributed objects (map, queue, topic, etc. instances). Starting with this release, the term "instance" is used for Hazelcast instances. The term "distributed object" is used for map, queue, etc. instances. You should replace the related methods with the new renamed ones. 3.0.x clients are smart clients in that they know in which cluster member the data is located, so you can replace your lite members with native clients.
public static void main( String[] args ) throws InterruptedException { HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap map = hazelcastInstance.getMap( "test" ); Collection<Instance> instances = hazelcastInstance.getInstances(); for ( Instance instance : instances ) { if ( instance.getInstanceType() == Instance.InstanceType.MAP ) { System.out.println( "There is a map with name: " + instance.getId() ); } } }with
public static void main( String[] args ) throws InterruptedException { HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(); IMap map = hz.getMap( "test" ); Collection<DistributedObject> objects = hazelcastInstance.getDistributedObjects(); for ( DistributedObject distributedObject : objects ) { if ( distributedObject instanceof IMap ) { System.out.println( "There is a map with name: " + distributedObject.getName() ); } } } -
Package structure change:
PartitionServicehas been moved to thecom.hazelcast.corepackage fromcom.hazelcast.partition. -
Listener API change: The
removeListenermethods were taking the listener object as a parameter. But this caused confusion since the same listener object may be used as a parameter for different listener registrations. So we have changed the listener API. TheaddListenermethods returns a unique ID and you can remove a listener by using this ID. So you should do the following replacement if needed:IMap map = hazelcastInstance.getMap( "map" ); map.addEntryListener( listener, true ); map.removeEntryListener( listener );with
IMap map = hazelcastInstance.getMap( "map" ); String listenerId = map.addEntryListener( listener, true ); map.removeEntryListener( listenerId ); -
IMap changes:
-
tryRemove(K key, long timeout, TimeUnit timeunit)returns boolean indicating whether operation is successful. -
tryLockAndGet(K key, long time, TimeUnit timeunit)is removed. -
putAndUnlock(K key, V value)is removed. -
lockMap(long time, TimeUnit timeunit)andunlockMap()are removed. -
getMapEntry(K key)is renamed asgetEntryView(K key). The returned object’s type (MapEntryclass) is renamed asEntryView. -
There is no predefined names for merge policies. You just give the full class name of the merge policy implementation:
<merge-policy>com.hazelcast.map.merge.PassThroughMergePolicy</merge-policy>Also the
MergePolicyinterface has been renamed asMapMergePolicyand returning null from the implementedmerge()method causes the existing entry to be removed.
-
-
IQueue changes: There is no change on IQueue API but there are changes on how
IQueueis configured: there is no backing map configuration for queue. Settings like backup count are directly configured on the queue configuration. See the Queue section. -
Transaction API change: Transaction API has been changed. See the Transactions chapter.
-
ExecutorService API change: The
MultiTaskandDistributedTaskclasses have been removed. All the functionality is supported by the newly presented interface IExecutorService. See the Executor Service section. -
LifeCycleService API: The lifecycle has been simplified. The
pause(),resume(),restart()methods have been removed. -
AtomicNumber:
AtomicNumberclass has been renamed asIAtomicLong. -
ICountDownLatch: The
await()operation has been removed. We expect users to useawait()method with timeout parameters. -
ISemaphore API: The
ISemaphorehas been substantially changed. Theattach(),detach()methods have been removed. -
Before, the default value for
max-sizeeviction policy was cluster_wide_map_size. Starting with this release, the default is PER_NODE. After upgrading, themax-sizeshould be set according to this new default, if it is not changed. Otherwise, it is likely thatOutOfMemoryExceptionmay be thrown.
